Data Science & ML/AI at Scale is Challenging.
Pandas is the most popular tool for data science/AI, with millions of dedicated users. With over 600 functions, pandas enables data scientists to quickly and flexibly clean, transform, summarize, and featurize data.
But pandas breaks down on large datasets, leading to out-of-memory errors and slow performance. At scale, the only alternative is to use the so-called “big data” frameworks, such as database systems or Spark.
Learn how Ponder's technology solves these challenges by empowering data science at scale, on any data infrastructure!
The Fragmented Data Stack
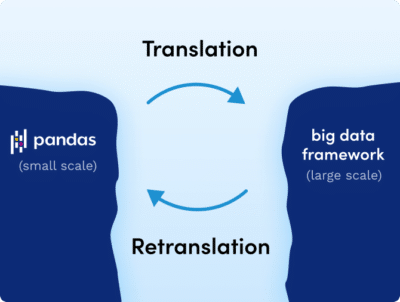
On the one hand, we have easy-to-use data science tools like pandas that operate on a small scale, and on the other hand, we have big data tools that are difficult to use but can operate at scale. For data science and ML use cases, Pandas is more convenient, concise, and flexible than big data tools like SQL, supported by data infrastructure for big data, like cloud-native data warehouses.
There is a huge divide between these two types of tools—data science tools that data scientists find easy to use at the small scale, and big data tools they are required to use at scale.
Fragmentation leads to loss of productivity and agility, wasted human capital, and diminished ROI.
At present, data scientists or data engineers spend valuable time rewriting pandas code written in the small scale to a big data framework such as SQL or Spark to run it at scale. This translation process can take many weeks to many months, resulting in fewer insights and fewer production deployments.
Once workloads have been translated and scaled, it becomes challenging to reconcile behavior on big data with what was observed at smaller scales. The only way to diagnose and address unexpected issues, performance regressions, and bugs is to retranslate back to pandas. And the cycle repeats, requiring costly translations and retranslations every step of the way, leading to organizational overheads.
Ponder solves the fragmentation challenges across the data stack.
Ponder helps you run the world's most popular data science/AI library, Pandas, as-is on the world's most popular data infrastructure, data warehouses.
Our solution, Ponder, is a drop-in replacement for Pandas, that provides seamless scalability, without requiring any changes to your code. Ponder entirely eliminates the fragmentation of the data stack. Data scientists can continue to use pandas on datasets at all scales without having to translate their code into a big data framework, or retranslate it back to pandas.
Ponder proprietary technology supports Pandas on cloud-native data warehouses, while Ponder's open-source library, Modin, supports Pandas on distributed computing infrastructure like Ray or Dask — either way, you're covered.
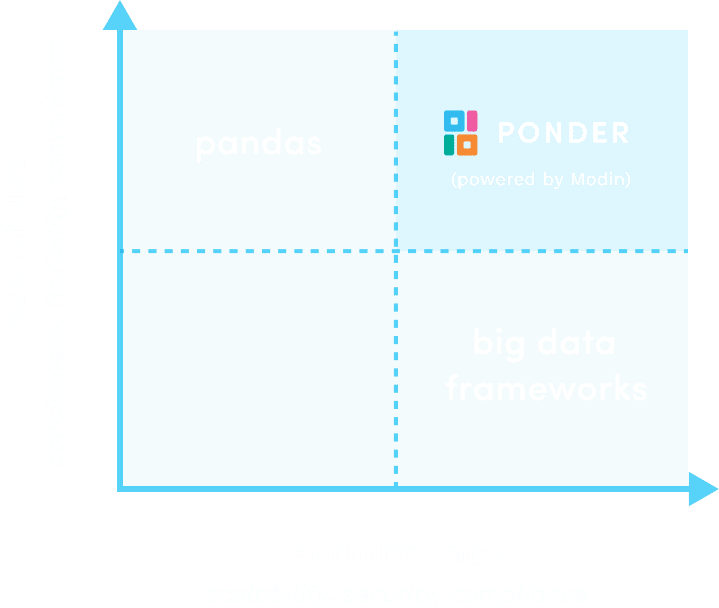
With Ponder, data scientists no longer need to pick between ease-of-use and scale.
Data scientists can now experiment at scale more rapidly, write less code and waste less time, and get more insights and models deployed. With Ponder, data stays in the data warehouse, with scalability, governance, compliance, privacy, and reliability all out-of-the-box. No additional infrastructure necessary. Ponder truly bridges the data science and big data worlds.

Ponder’s open-source tool, Modin, is trusted by organizations across sectors.
Modin is used by 10% of the Fortune 100 companies, and is employed by companies in several industries including automotive, software, hardware, AI, pharmaceutical, financial services, among others. Modin has been embraced by the open-source community, with over 5M downloads. Companies across the globe are benefiting from the productivity boost when their data stack is no longer fragmented.
Ponder’s technology is deeply rooted in cutting-edge research from UC Berkeley.
Ponder’s technology is based on decades of academic research and development, with multiple published papers at the top academic conferences and journals. We draw on scalability ideas from database systems and distributed systems—and apply it to data science/AI tools like Pandas.
We do the hard work so you don't have to. Check out our papers here:
Flexible Rule-Based Decomposition and Metadata Independence in Modin
VLDB 2021
Enhancing the Interactivity of Dataframe Queries by Leveraging Think Time
IEEE Data Eng 2021
Dataframe Systems: Theory, Architecture, and Implementation
PhD Dissertation 2021
Scaling Data Science does not mean Scaling Machines
CIDR 2021
Towards Scalable Dataframe Systems
VLDB 2020