

TLDR: In this post, we show that Modin can speed up machine learning workflows by 10X or more, on tasks like performing sentiment analysis with the Hugging Face Transformers library.
According to Stack Overflow’s latest developer survey, the most loved library in the Python community is Hugging Face’s Transformers, which features pre-trained, state-of-the art language models for things like paraphrasing and sentiment analysis. But there’s no such thing as a free lunch. To run these complex models in a reasonable amount of time and without crashing your system, manual optimizations and GPU-based hardware configurations are typically required. But fear not, Modin allows you to get improved performance directly on your laptop or in the cloud on commodity CPUs!
Our open-source project, Modin, is a scalable, drop-in replacement for pandas. Keep using your favorite pandas syntax from exploration and pre-processing through to inference. No more out-of-memory errors, no more wasted resources, no more hand-tuning and optimization required. Under the hood, Modin improves the way your data is handled in memory and distributes your workloads across the resources available in your environment.
If you want to learn more about how Modin can speed up your Hugging Face workloads by 10X, this post is for you! You can try out the notebook version of this blog post on Github here.
How it Works
Today, if you were to read in your data into a pandas dataframe and use a Transformer model for sentiment analysis, the execution would be done serially because of pandas’ single-threaded design — only one core on your machine would be utilized.
Modin parallelizes the execution without requiring you to change your pandas code. Under the hood, Modin improves the utilization of your environment’s resources — whether on your local machine or in the cloud. Modin automatically partitions your dataframe into many different components on which your NLP models can be run at the same time.
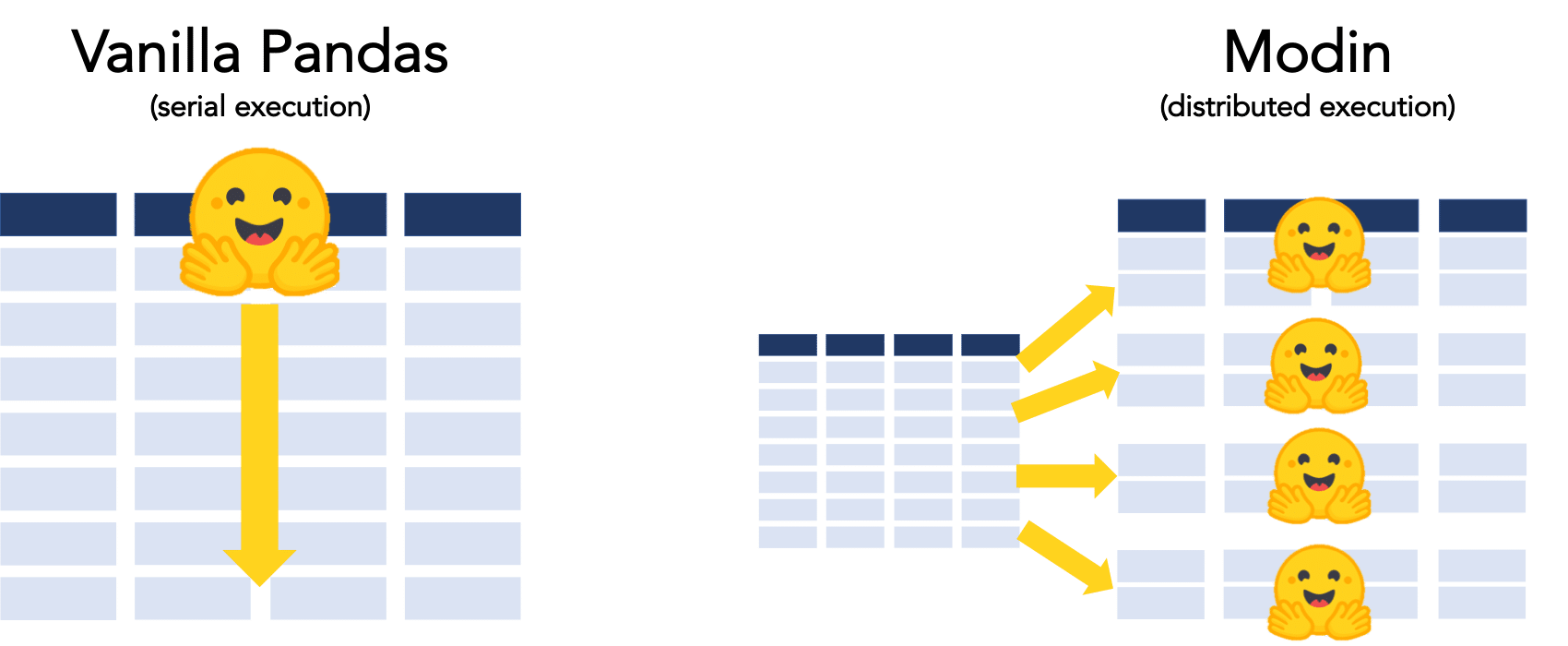
To illustrate this, we created an example using Yelp’s public restaurant review data set, Modin, and the Hugging Face Transformers library.
- Use Case: Compare customer sentiment between Taco Bell and other Mexican restaurants.
- Data Set: Restaurant reviews data set with ~5M records, which you can find on Kaggle
- Infrastructure: AWS instance with 16 vCPUs and 64GB of memory
Our example illustrates the differences between using vanilla pandas and Modin across these steps:
- Install + Import Requirements
- Read in the Data
- Explore the Data
- Pre-Process the Data
- Define Sentiment Analysis Pipeline
- Execute the Sentiment Analysis Pipeline
Step 0: Install + Import Requirements
Install Modin on your machine, whether on your laptop or in the cloud. See the docs for more information.
!pip install modin[all]Import vanilla pandas and Modin for comparison. Note that by changing one line of import, Modin allows you to work with pandas at scale.
import pandas as old_pd
import modin.pandas as pdImport other dependencies, including Hugging Face Transformers.
#Hugging Face
from transformers import DistilBertTokenizer
from transformers import pipeline
#miscellaneous
import timeStep 1: Read in the Data
We will be using Yelp’s publicly available business profile information (name, location, category) and the reviews of those businesses, which we have stored in two CSV files on s3. The combined data set is almost 5M records and 4GB.
Reading from S3 with pandas
%%time
business=old_pd.read_csv("s3://my-ponder-demos/business.csv")
reviews=old_pd.read_csv("s3://my-ponder-demos/review.csv")
Reading from S3 with Modin
%%time
business=pd.read_csv("s3://my-ponder-demos/business.csv")
reviews=pd.read_csv("s3://my-ponder-demos/review.csv")
🔥🔥🔥 ~3X Speedup on Reading from S3 🔥🔥🔥
Step 2: Explore the Data
Now, to familiarize ourselves with the data, we print the top three rows of our dataframes.
Modin mirrors the pandas user experience, including everything from the syntax of the commands, formatting of the results, and even errors and exceptions.
Note how the first few rows of these dataframes look the same, whether we use Modin or pandas.
# What's in a review?
reviews.head(3)
# What's in a business profile?
business.head(3)
Modin mirrors the pandas user experience.
Step 3: Pre-Process the Data
As is usually the case with NLP problems, we need to pre-process the data before we can apply our language models. This includes operations like lowercase conversion or truncation. Here, we apply a series of pre-processing steps to create additional features based on the text reviews. As seen below, Modin can deliver out-of-the-box speed ups on these feature engineering steps.
Pre-Processing with Pandas
%%time
# lower case review text
reviews['text'] = reviews.text.str.lower()
# get the length of each review
reviews['length'] = reviews['text'].apply(lambda x: len(x))
reviews = reviews.sort_values(by=['length'], ascending=False)
# drop rows that have a length of more than 512 characters, model can't handle them
reviews.drop(reviews[reviews['length'] >= 512].index, inplace = True)
# drop the entire length column - we don't need it anymore
reviews.drop('length', axis=1, inplace=True)
# Add "Is Mexican Food Flag"
business['is_mexican_food'] = business['categories'].str.lower().str.contains("burrito|taco|mexican|tex-mex")
reviews = reviews.merge(business[["business_id","name", "is_mexican_food"]],how="left",on="business_id",suffixes=('', '_y'))
#Subset to mexican restaurants
mexican_food_reviews = reviews[reviews.is_mexican_food==True]
Pre-Processing with Modin
%%time
# lower case review text
reviews['text'] = reviews.text.str.lower()
# get the length of each review
reviews['length'] = reviews['text'].apply(lambda x: len(x))
reviews = reviews.sort_values(by=['length'], ascending=False)
# drop rows that have a length of more than 512 characters, model can't handle them
reviews.drop(reviews[reviews['length'] >= 512].index, inplace = True)
# drop the entire length column - we don't need it anymore
reviews.drop('length', axis=1, inplace=True)
# Add "Is Mexican Food Flag"
business['is_mexican_food'] = business['categories'].str.lower().str.contains("burrito|taco|mexican|tex-mex")
reviews = reviews.merge(business[["business_id","name", "is_mexican_food"]],how="left",on="business_id",suffixes=('', '_y'))
#subset to mexican restaurants
mexican_food_reviews = reviews[reviews.is_mexican_food==True]

🔥 Almost 2X Faster Pre-Processing 🔥
Step 4: Define Sentiment Analysis Pipeline
Now that we’ve prepared the data, we are ready to get to the modeling steps. To compare the sentiment of Taco Bell reviews versus other Mexican restaurants, we’ll need to first classify the sentiment of each review in our dataset. Transformers lets us build sentiment analysis pipelines using the pipeline interface.
We define a pipeline that does tokenization and the sentiment classification below.
db_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
classifier = pipeline("sentiment-analysis", model="j-hartmann/emotion-english-distilrobertabase",max_length=512,truncation=True, tokenizer= db_tokenizer)
def sentiment_classifier(text):
classifier_results = classifier(text)[0]
return classifier_results['label'],classifier_results['score']
Step 5: Execute the Sentiment Analysis Pipeline
Finally, we run our classification pipeline to label the sentiment (joy, sadness..etc) of each review and generate a confidence score to go along with that label. We can see the benefits of Modin’s distributed execution and improved memory management below.
Sentiment Analysis with Pandas
%%time
mexican_food_reviews['sentiment'],mexican_food_reviews['score'] = zip(
*mexican_food_reviews.apply(lambda x: sentiment_classifier(x['text']),axis=1))Above, pandas only uses one of the 16 available CPUs on my machine and crashes when I run out of memory. As discussed previously, the pandas implementation of the apply operator is only evaluating the sentiment on one review at a time.
😩😩😩 System Crashes After 5 Hours!! 😩😩😩
The Modin implementation below has an identical syntax, but parallelizes the apply so that the sentiment can be evaluated on many reviews at the same time.
Sentiment Analysis with Modin
%%time
mexican_food_reviews['sentiment'],mexican_food_reviews['score'] = zip(
*mexican_food_reviews.apply(lambda x: sentiment_classifier(x['text']),axis=1))
Because Modin is able to utilize all of the CPU’s in the environment and manage memory more efficiently, we avoid crashing the system and get results much faster!
12X Faster + More Reliable Hugging Face Inference
Conclusion:
To recap, in this post we demonstrated that Modin isn’t only useful for scaling simple pandas workflows, but can also help accelerate your ML pipelines and workloads.
If you’re curious to know how Taco Bell ranked in the results, found this post useful, or want to share how you’re using Modin in your workflows, we would love to hear from you! Follow us on Twitter or Linkedin or check out what we’re building here!



