

Introduction to pandas resample
A common time series challenge is having data represented with the wrong time interval for your use case — Perhaps you want your data expressed per hour, but it’s expressed per minute, making it hard to join your data with another hourly data set.
The solution? Resampling. In this article, we describe pandas resample + provide some examples, and then show how you can use it at scale in your database. For more examples of pandas time series functionality (including additional pandas resample details), check out our Professional Pandas article: “Python for Finance: Pandas Resample, Groupby, and Rolling.”
What Does pandas resample do?
pandas resample allows for easy frequency conversion and aggregations across intervals for dataframes and series with certain types of indexes: DatetimeIndex, PeriodIndex, and TimedeltaIndex.
It supports a variety of frequencies to resample by, including minutes, hours, days, quarters, and years and several aggregations to be applied on the data.
There are two types of resampling: downsampling and upsampling. We’ll walk through simple examples of both.
Let’s start by imagining we have a Series with a DatetimeIndex minutes_time and several integer values:
minutes_time
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
Name: a, dtype: int64In downsampling, we use a wider frequency to grouping the DatetimeIndex by the desired interval. In the examples below, we downsample by interval 3 minutes and 10 minutes, applying the aggregations min and mean respectively.
ser.resample("3min").min()minutes_time
2000-01-01 00:00:00 0
2000-01-01 00:03:00 3
2000-01-01 00:06:00 6
Name: a, dtype: int64ser.resample("10min").mean()minutes_time
2000-01-01 4
Name: a, dtype: int64In upsampling, we use a narrower frequency, resulting in many rows being populated with NaN values. In the example below, we upsample by the interval 30 seconds with the aggregation min.
ser.resample("30S").min()
minutes_time
2000-01-01 00:00:00 0.0
2000-01-01 00:00:30 NaN
2000-01-01 00:01:00 1.0
2000-01-01 00:01:30 NaN
2000-01-01 00:02:00 2.0
2000-01-01 00:02:30 NaN
2000-01-01 00:03:00 3.0
2000-01-01 00:03:30 NaN
2000-01-01 00:04:00 4.0
2000-01-01 00:04:30 NaN
2000-01-01 00:05:00 5.0
2000-01-01 00:05:30 NaN
2000-01-01 00:06:00 6.0
2000-01-01 00:06:30 NaN
2000-01-01 00:07:00 7.0
2000-01-01 00:07:30 NaN
2000-01-01 00:08:00 8.0
Name: a, dtype: float64Now that we have seen some basic examples of how pandas resample works, let’s try it out on some large data!
pandas resample on a Database
Ponder lets you use the pandas API on data in your data warehouse, and it does this by converting your pandas code to SQL. We currently support resample on Snowflake, DuckDB, and BigQuery. For more details on our resample API coverage, see our Supported API documentation here.
Let’s go through an example of downsampling on Snowflake. First we initialize Ponder and connect it to our Snowflake data warehouse:
import snowflake.connector
import modin.pandas as pd
import ponder
# Create a Ponder Snowflake Connection Object
snowflake_con = snowflake.connector.connect(
user=******,
password=******,
account=******,
role=******,
database=******,
schema=******,
warehouse=******,
)
ponder.init()
ponder.configure(default_connection=snowflake_con)Next we read a Snowflake table with 150 million rows into our dataframe and set the index O_ORDERDATE, which is a datetime column.
df_orders = pd.read_sql("SELECT * FROM PONDER_DEMO.ORDERS_150M", snowflake_con)
df_orders.set_index("O_ORDERDATE", inplace=True)
df_orders
Finally, we resample by a yearly interval and aggregate the results by performing a mean.
df_orders.resample("Y").mean()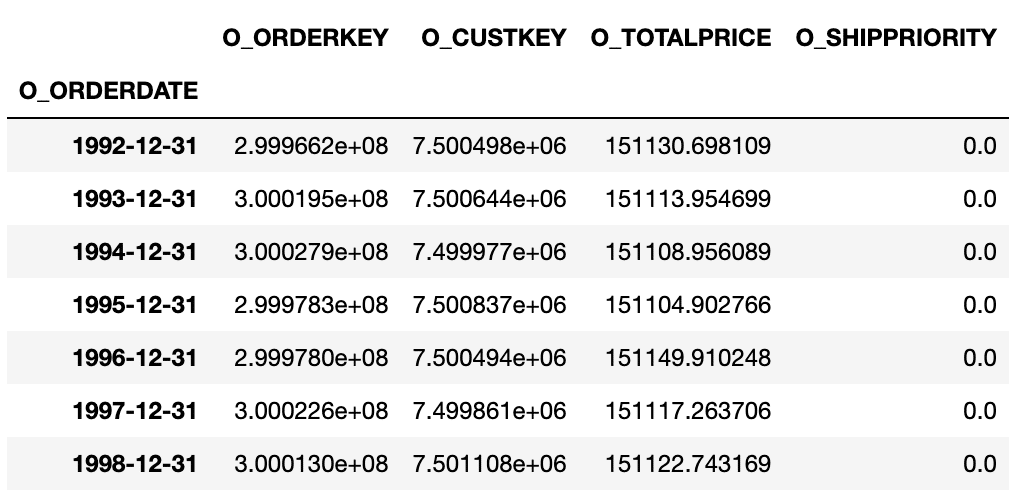
In the above table, you can see that the index is now grouped by every year in the index, and the values are an average per group of each of the columns. Our resampling operation was successful!
This 150M-row resample.mean operation took only ~18 seconds on an x-small Snowflake warehouse, while the equivalent operation took ~2 minutes in pandas (2.3 GHz 8-Core Intel Core i9 MacBook Pro). That’s a ~6.5X speedup!
Summary
In this post, we discussed what pandas resample does and how to use it. We then demonstrated running pandas.resample directly in your data warehouse with Ponder.
If you want to give resample a try on your own data warehouse, Try Ponder Today!
Try Ponder Today
Start running your Python data science workflows in your database within minutes!



