

If you use Python dataframes that aren’t pandas (Modin, Dask, cuDF, Polars, etc.), you should know about the Python DataFrame Interchange Protocol. It’s a quiet hero that’s likely saving you many headaches, and since gratitude comes with lots of health benefits, it’s worth taking a moment to give thanks!
In this article, we answer three questions about the protocol:
- What is the Python Dataframe Interchange Protocol, and what problem does it solve?
- How do libraries implement the protocol?
- How extensively has it been adopted?
What is the Python Dataframe Interchange Protocol, and what problem does it solve?
The protocol exists to make it easy to “convert one type of dataframe into another type” — Modin to pandas, Polars to cuDF, etc.
So if you rarely convert dataframes from one type to another, why should you care? Because dataframe libraries aren’t used in isolation — dataframes frequently get passed as inputs to viz or ML libraries — and the protocol makes it possible “to write code that can accept any type of dataframe instead of being tied to a single type of dataframe.” Without the protocol, it’s hard for Python library maintainers (seaborn, plotly, etc.) to support an assortment of dataframe types. With it, they have a straightforward path to accepting any dataframe that’s protocol-compatible.
We’ve seen the benefits of the protocol firsthand at Ponder because we maintain Modin, the drop-in scalable replacement for pandas with more than 11 million downloads, and we’ve encountered a number of instances where a plotting or ML library might have a hard-coded assert statement to check that the input is a pandas dataframe, and not just a Python dataframe. Thanks to the protocol, maintainers are starting to remove these pandas-only restrictions, and it’s getting easier and easier for non-pandas dataframe users in the Python ecosystem to utilize their tool of choice rather than one that is compatible with their current stack.
How do libraries implement the protocol?
There are two parts to this:
- Python dataframe libraries have to make a series of changes so they conform to the protocol.
- Non-dataframe libraries need to make changes so that they reference the generic protocol methods instead of referencing pandas specifically, or they can continue referencing pandas and use the protocol to “convert” the other dataframe to a pandas dataframe (ideally without adding the overhead of actually copying the data — we’ll talk more about this in a second).
We’ll address how each of these — the dataframe libraries, and the libraries that take in dataframes — implements or adopts the protocol.
How does a dataframe library adopt the protocol?
The protocol defines a series of base classes and methods — you can see the file here — and this is the template that each dataframe library needs to flesh out to be compatible with the protocol.
Mechanically, the protocol ensures that the dataframe library has implemented everything by decorating each method with the abstractmethod decorator from the abstract base classes (“abc”) module. You can think of this as a “you absolutely must do this!” message from the protocol creators to the dataframe maintainers. If the maintainers don’t re-implement that method, users who try to use the dataframe will get an error when they try to create any object from a class that has that method.
There aren’t that many parts to the protocol — eight classes, three of which have associated methods — so we’ll briefly describe them here in three buckets.
The first bucket consists of three classes that map attributes to integers (enums):
- DlpackDeviceType (e.g., the device type “CPU” equals 1)
- DtypeKind (e.g., the data type “int” equals 0)
- ColumnNullType (e.g., the null type “use_nan” equals 1)
The second bucket consists of classes of typed dicts (which are just turbocharged dictionaries that also let you specify the type of the data being stored — boolean, tuple, etc.):
- ColumnBuffers (e.g., “data” is a tuple of the buffer of column data and the data type)
- CategoricalDescription (e.g., “is_ordered” is a boolean indicating “whether the ordering of dictionary indices is semantically meaningful”)
The third bucket consists of the three classes that have methods — these are doing the heavy lifting:
- Buffer (methods: bufsize, ptr, __dlpack__, __dlpack_device) (a block of memory that helps expose raw byte arrays to other Python objects such as arrays)
- Column (methods: size, offset, dtype, describe_categorical, describe_null, null_count, metadata, num_chunks, get_chunks, get_buffers)
- DataFrame (methods: __dataframe__, metadata, num_columns, num_rows, num_chunks, column_names, get_column, get_column_by_name, get_columns, select_columns, select_columns_by_name, get_chunks)
The easiest way to understand at a high level what’s going on with the above classes is to see how they’re implemented in other projects.
Taking Modin as an example, we see that there’s a dataframe_protocol directory that has several files in it, the most important of which are buffer.py, column.py, and dataframe.py. These correspond to the final three classes listed above (the ones with methods), and if you open up any of these files, you’ll see that the Modin maintainers had to use Modin’s internals to implement each of the required methods.
So, for example, there’s the “size()” method in column.py that gives you the size of a column:
def size(self) -> int:
return len(self._col.index)This fills in the scaffolding set out by the protocol template we discussed above, which is just a hollow shell. For size(), it consists of a docstring and a “pass”:
@abstractmethod
def size(self) -> int:
"""
Size of the column, in elements.
Corresponds to DataFrame.num_rows() if column is a single chunk;
equal to size of this current chunk otherwise.
Is a method rather than a property because it may cause a (potentially
expensive) computation for some dataframe implementations.
"""
passThere’s nothing magic about the process. The Modin maintainers just had to go through and implement each method in the protocol.
To learn how all this comes together, it’s best to see the protocol in action, and for that we need to look at how non-dataframe libraries make use of it to flexibly accept dataframes of all flavors.
How does a non-dataframe library make use of the protocol?
Let’s look at plotly, which started using the Python Dataframe Interchange Protocol at the end of June, 2023.
Before implementing the protocol, plotly used the build_dataframe() function to convert its input to a pandas dataframe, assuming that the input — “an existing columns of a dataframe, or data arrays (lists, numpy arrays, pandas columns, series)” — would either have a to_pandas() method, or could be passed into the pandas DataFrame constructor, pd.DataFrame().
To make use of the protocol, it now instead firsts checks if the input has the __dataframe__ method (required by the protocol), and if it does, it imports pandas.api.interchange and then calls the function pandas.api.interchange.from_dataframe() on that input. Then if that doesn’t work, it goes through its previous routine of trying to_pandas() and the pd.DataFrame() constructor, in that order. So it’s still converting the inputs to pandas, but now in a much more universal way.
If we go look at pandas.api.interchange, we see that this file actually imports from_dataframe(), and from_dataframe() uses the tools provided by the protocol to take any protocol-compliant dataframe and convert that to pandas.
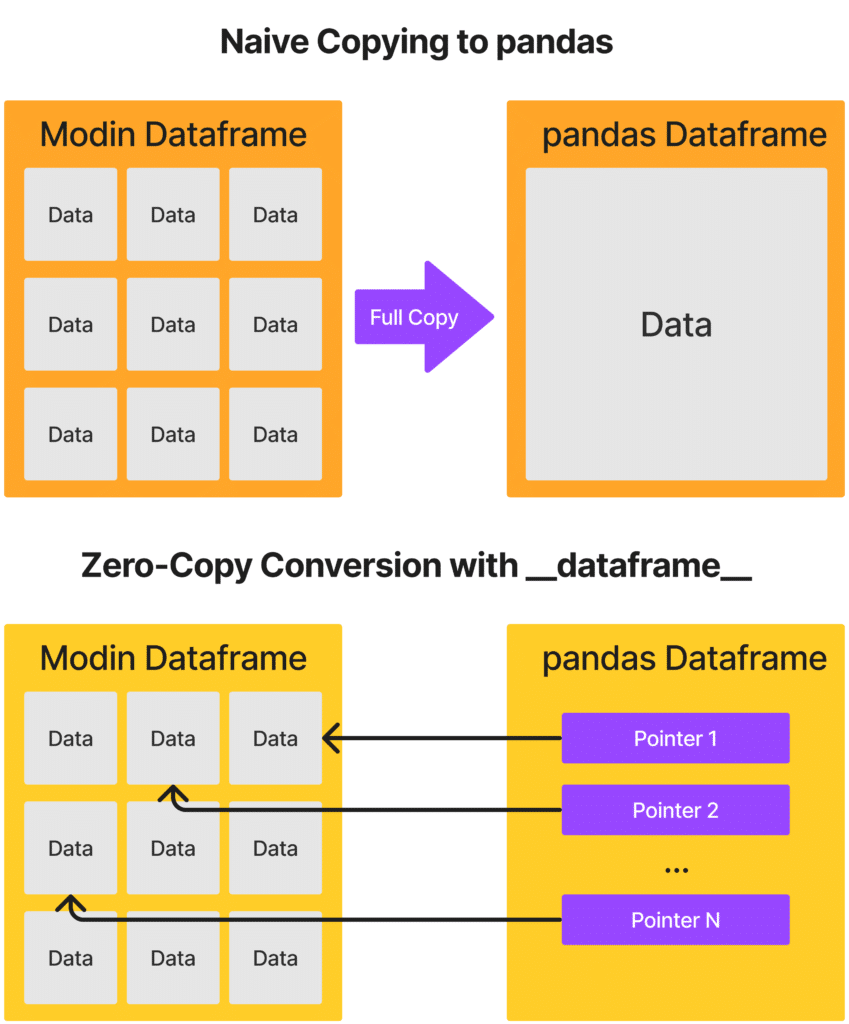
One of the most elegant aspects of this system is that, whenever possible, the protocol tries to have these conversions happen in a “zero-copy” way. Loosely speaking, this means that the converted dataframe is more like a view on or pointer to the old dataframe, so this involves a lot less overhead than if you had to do a full copy of the data into a new format.
How extensively has the protocol been adopted?
The Python dataframe libraries that have adopted the protocol include (ordered by pull request date):
- Vaex (PR merged 10/13/21)
- cuDF (PR merged 11/17/21)
- Modin (PR merged 2/25/22)
- pandas (PR merged 4/27/22)
- Polars (PR merged 1/30/23) — building off of pyarrow’s implementation (PR merged 1/13/23)
- ibis (PR merged 6/16/23)
The non-dataframe libraries that use the protocol include (ordered by pull request date):
- Altair (PR merged 2/18/23)
- scikit-learn (PR merged 6/21/23)
- Plotly (PR merged 6/30/23)
- Seaborn (PR merged 8/23/23)
Conclusion
The Python Dataframe Interchange Protocol is a major development in the Python ecosystem that makes it simple for libraries to support many types of dataframes and thus bridges the gap for users to choose data science tools without concern for library compatibility. It’s already making a difference for Plotly, Seaborn, Altair, and scikit-learn users, but there are many other libraries that still could rely on it. If you encounter problems getting your non-pandas dataframes to work with one of those, submit an issue, and reference the protocol as a solution!
About Ponder
Ponder is the company that lets you run your Python data workflows (in Pandas or NumPy) securely, seamlessly, and scalably in your data warehouse or database. Sign up for a free trial!
Try Ponder Today
Start running your Python data science workflows in your database within minutes!



