

If you start digging into the world of PyTorch — one of the most popular deep learning libraries — one of the first things you’ll learn is how to work with a PyTorch DataLoader. (In PyTorch’s “Learn the Basics” tutorial, the “Datasets and DataLoaders” section is second, coming only after Tensors.)
For a very long time, at least since version 0.1.12, the DataLoader has had a batch loading option so you don’t have to load rows one by one. In this article, we discuss how Modin — the open-source scalable drop-in replacement for pandas — now implements a version of the PyTorch DataLoader that supports batch loading as well, making it much, much faster to use PyTorch as a Modin user.
What Does the PyTorch DataLoader Do?
An obvious answer is to say “it loads data,” but that’s about as helpful as this.
The documentation states that the “DataLoader wraps an iterable around the Dataset to enable easy access to the samples,” which basically means that the DataLoader is the tool that lets you easily pull data (with multiple workers, in batches, using various sampling methods, etc.) from the Dataset and feed that data into a model you want to train.
Since training a model with PyTorch typically happens iteratively (in epochs, where an epoch is one full run of your training data), not having a DataLoader would mean a lot more work for the user: You’d have to keep track of which batches of data you’ve already used to train your model, you’d have to implement the sampling method of your choice, you’d have to handle parallelization across multiple workers, and more. It would be messy.
Why Is the ModinDataLoader an Improvement for Modin Users?
When working with the normal PyTorch DataLoader, Modin users can’t do batch loading, even if they specify a batch_size greater than 1. But with the new ModinDataLoader, batch loading is possible. (Note that even with the current ModinDataLoader, we’re still not doing distributed batch loading — But if you’re reading this and want to build that out, please give it a shot! That’s the beauty of open source.)
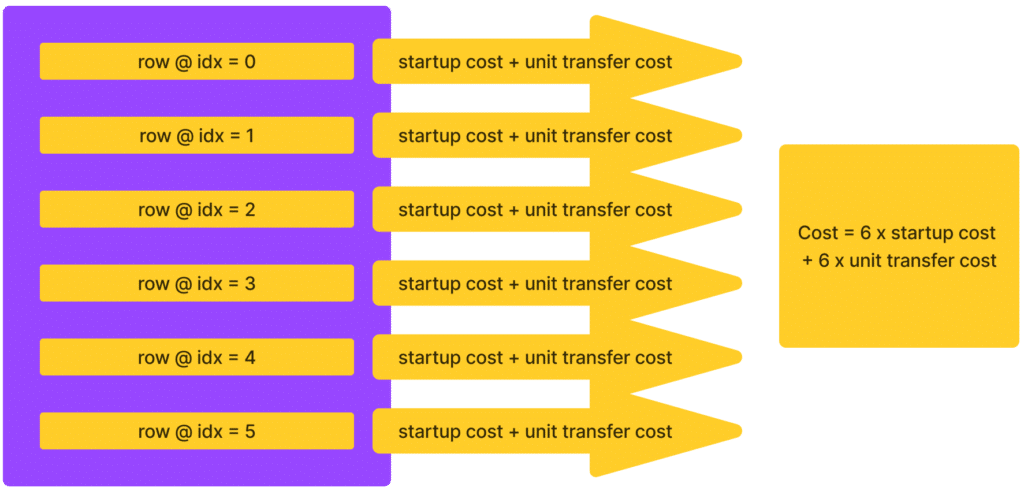
We can visualize life for Modin users with the PyTorch DataLoader with the following stylized example. If you were loading six rows of data before, you’d have to pay a startup cost (largely due to network latency, we believe) + the cost for transferring that amount of data each time you loaded a single row.
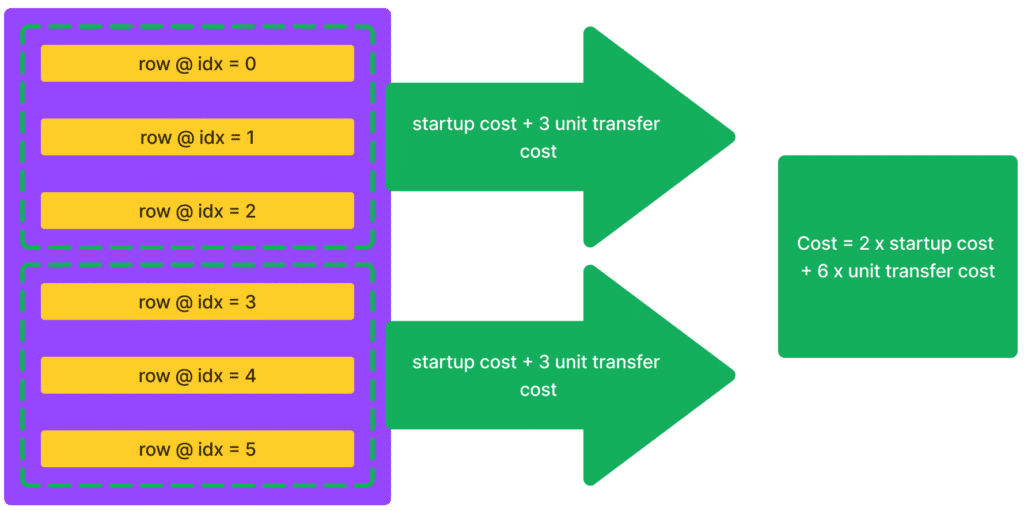
But now, by batching, you effectively amortize that startup cost over multiple rows, reducing the total time it takes to load the data.
How Much Faster Is Modin + PyTorch Now?
Let’s start by getting a baseline. First, make sure you’ve pip installed torch, NumPy, tqdm (for seeing the progress bar as we train our model), and Modin. For Modin, since the new ModinDataLoader is in the main branch but not the yet in the most recent stable release, you’ll have to pip install it directly from the repo as follows:
! pip install git+https://github.com/modin-project/modin.gitImport everything you’ll need:
import modin.pandas as pd
import torch
import numpy as np
from tqdm import tqdmNow we’ll load in a csv file with 5000 rows (in this case, a housing dataset), list out the features in that dataset, and initialize three things: an incredibly simple model (a single linear layer with 5 weights), a loss function, and an optimizer.
df = pd.read_csv(
"https://raw.githubusercontent.com/ponder-org/ponder-datasets/main/USA_Housing.csv"
)
features = [
"AVG_AREA_INCOME",
"AVG_AREA_HOUSE_AGE",
"AVG_AREA_NUM_ROOMS",
"AVG_AREA_NUM_BEDROOMS",
"POPULATION",
"PRICE",
]
model = torch.nn.Linear(5, 1)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())Now we split up our data into training and test sets:
from sklearn.model_selection import train_test_split
df_train, df_test = train_test_split(df)We define our training loop:
def train_from_loader(model, loss_fn, optimizer, loader):
for batch in tqdm(loader):
# Do your machine learning stuff here.
features = torch.tensor(batch[:, :-1]).float()
target = torch.tensor(batch[:, -1]).float()
# Generate outputs
output = model(features).squeeze()
loss = loss_fn(output, target)
# Compute gradients.
optimizer.zero_grad()
loss.backward()
optimizer.step()Test 1: Modin with the existing DataLoader
Then we wrap our data into a Dataset (basically a list), and then wrap that Dataset into a DataLoader. Note that here, we’re using the out-of-the-box PyTorch DataLoader, and not the new ModinDataLoader.
class HousingDataset(torch.utils.data.Dataset):
def __init__(self, dataframe):
self._df = dataframe
def __len__(self):
return len(self._df)
def __getitem__(self, index: int):
# Convert to numpy arrays because torch recognizes it.
return np.array(self._df.iloc[index])
loader = torch.utils.data.DataLoader(HousingDataset(df_train[features]), batch_size=64)And finally, the moment we’ve all been waiting for! We train our model and see how fast (or slow, in this case) it is when using Modin + torch.utils.data.DataLoader:
%%time
train_from_loader(model, loss_fn, optimizer, loader)CPU times: user 4.21 s, sys: 1.83 s, total: 6.05 s
Wall time: 8.77 sIt took 8.56 seconds on a 2021 M1 MacBook Pro (16 GB of memory), even though we’d specified a batch_size of 64. If we run this again using a batch_size of 1, we get basically the same results (9.81 seconds).
Test 2: Modin with the New DataLoader (ModinDataLoader)
So what happens when we use the new ModinDataLoader instead? We see a 56X speedup.
from modin.experimental.torch.datasets import ModinDataLoader
loader = ModinDataLoader(df_train, batch_size = 64, features = features, sampler=torch.utils.data.SequentialSampler)%%time
train_from_loader(model, loss_fn, optimizer, loader)CPU times: user 75.4 ms, sys: 21.8 ms, total: 97.2 ms
Wall time: 156 msThe ModinDataLoader Also Works with Ponder
Ponder is built on Modin, but differs in that it lets you run your Python data workflows (in Pandas or NumPy) directly in your data warehouse or database (Snowflake, BigQuery, DuckDB). If you’re using Ponder on the open-source database DuckDB, you can even run this locally. Sign up for a free trial!
The good news is the new ModinDataLoader also works with Ponder! The only code difference is that we have to import Ponder and DuckDB, and also initialize and configure Ponder:
import duckdb
import ponder
ponder.init()
ponder.configure(default_connection=duckdb.connect())Conclusion
If you use PyTorch and Modin, your life just got a lot easier: Now you can use the ModinDataLoader, a version of the PyTorch DataLoader that’s built specifically to work well with Modin. On the small example above, we see a 56X speedup.
Try Modin today. Or if you want to run your pandas code directly on a database (one of the most optimized computation engines there is), try Ponder.
Try Ponder Today
Start running your Python data science workflows in your database within minutes!



