

pandas apply is a powerful operation that lets users execute custom operations on their DataFrames. In this article, we’ll explore how pandas apply works and demonstrate how you can leverage Ponder to directly perform pandas apply on your database.
What is pandas.DataFrame.apply?
pandas apply applies a Python function along an axis of the DataFrame. The function can usually be any user-defined function or one defined in an external library, etc. This functionality provides users a lot of flexibility as they can perform custom computations or analyses at a row or column-wise level. For example, users may specify a custom formula for calculating a particular metric of interest or define a custom scoring function to evaluate the result of a model.
Here is an example of howapplyworks in practice, we create an example dataframe with two columns. We useapplyto create a third columncbased on the average of the two existing columnsaandb. The operation is applied along the columns as specified byaxis=1.
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
df['c'] = df.apply(lambda row: (row.a + row.b) / 2, axis=1)
df
| a | b | c | |
|---|---|---|---|
| 0 | 1 | 4 | 2.5 |
| 1 | 2 | 5 | 3.5 |
| 2 | 3 | 6 | 4.5 |
apply allows users to perform custom functions on every value in your dataframe without having to loop over every value in a DataFrame/Series explicitly. It is well known that looping over DataFrames can be slow and inefficient, making your pandas code difficult to optimize. Note that while apply is often considered better practice than looping over something like iterrows(), it is not a vectorized implementation and can still lead to slowness.
At Ponder, our goal is to provide the same seamless experience of pandas on top of your existing data warehouses. Thus, supportingapplyto work in the same fashion you would expect in pandas has been a priority for us. We currently supportapplyonly on Snowflake and DuckDB, but are working hard to get it to work on other DB vendors as well. Here's an example of us runningapplywith Ponder on Snowflake:
import ponder
ponder.init()
import modin.pandas as pd
import snowflake.connector
# Create a Ponder Snowflake Connections object
snowflake_con = snowflake.connector.connect(
user=credential.params["user"],
password=credential.params["password"],
account=credential.params["account"],
role=credential.params["role"],
database=credential.params["database"],
schema=credential.params["schema"],
warehouse=credential.params["warehouse"]
)
df = pd.read_sql("TAXI", header=0)
Here, we do a simple calculation where we add 1000 to every value in TRIP_DISTANCE.
df[['TRIP_DISTANCE']].apply(lambda x: x+1000, axis=1)
| TRIP_DISTANCE | |
|---|---|
| 0 | 1011.89 |
| 1 | 1012.58 |
| 2 | 1001.01 |
| 3 | 1002.27 |
| 4 | 1001.76 |
| … | … |
| 14995 | 1000.66 |
| 14996 | 1001.89 |
| 14997 | 1007.50 |
| 14998 | 1007.36 |
| 14999 | 1003.00 |
15000 rows x 1 columns
We can do something more advanced here to calculate the fare price per passenger, while custom-handling the cases where the passenger count is zero to avoid division by zero error.
# Calculate fare per passenger
def func(row):
if row['PASSENGER_COUNT'] > 0:
return row['FARE_AMOUNT'] / row['PASSENGER_COUNT']
return 0
df.apply(func, axis=1)
0 34.00
1 38.50
2 6.50
3 1.90
4 1.60
...
14995 2.25
14996 4.25
14997 23.50
14998 11.25
14999 5.75
Length: 15000, dtype: float64
How does apply work in Ponder?
The ability to run arbitrary Python functions and leverage pandas apply to apply them to a dataframe seems like magic. Let’s take a look at how this works underneath the hood.
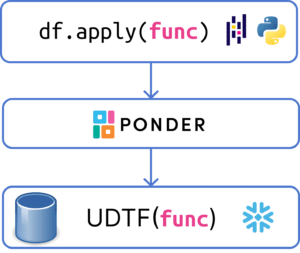
To run arbitrary Python functions within your database, we create a temporary Python user-defined table function (UDTF) in Snowflake based on the function that the user submitted in the apply.
As an aside, you might have heard of UDFs and are wondering how UDTFs are different. UDFs are scalar functions designed to return a row of values, so the results will be a single row/column. For example, in the pandas apply example at the beginning of this post, every value in column c is equal to the corresponding value in column a plus the corresponding value in column b divided by two. UDTFs are just like UDFs but instead, they return a table of values. So if we want the output to be a DataFrame, UDTFs are the way to go.
Summary
In this quick post, we demonstrate how you can run pandas apply on your DataFrame directly with the data in your data warehouse. If you want to try this out on your own, sign up for Ponder for free here!



