

Until now, if you wanted to do large-scale Python work in GCP, you had a few options: Splurge for expensive compute instances through Vertex AI; sacrifice being able to work with pandas and instead use pyspark with Dataproc; or settle for working with a sample of data on a cheaper Vertex AI instance.
Ponder lets you have it all by being your pandas interface for BigQuery: You can use an affordable Vertex AI Notebook, continue using pandas, and work with your whole dataset. All because Ponder lets you write pandas code in Vertex AI while using BigQuery as the serverless compute engine.
What’s in this post:
- Installing and setting up Ponder on Vertex AI
- Connecting to BigQuery from Vertex AI
- Copying a BigQuery Public dataset to your project
- Working with BigQuery data using pandas dataframes in Vertex AI
- Ready for something big?
- Vertex AI + Ponder: Wrapping it all up
Note that even though in this post we’re focusing on Vertex AI in the GCP ecosystem, Ponder works with many IDEs and databases.
Try Ponder Today
Start running your Python data science workflows in your database within minutes!
Installing and setting up Ponder on Vertex AI¶
Vertex AI is an end-to-end machine learning platform provided by Google Cloud that allows developers to develop and deploy ML models. Vertex AI’s Workbench includes a managed notebook service that lets you develop and iterate on your data science/ML workflows.
Note: We will be using Vertex’s User-Managed Notebooks in this tutorial. Managed Notebooks come with an older version of Python (3.7) that is not compatible with Ponder (requires 3.8 or higher). If you are using “Managed Notebook,” please follow these instructions to create a Python 3.9 environment to install Ponder.
First, we create a user-managed notebook in the Vertex AI workbench. Here, we pick the cheapest and most lightweight instance available (n1-standard-1), which only has 1 CPU and 3.75GB of RAM. As we will explain later in this post, this is aimed to showcase that you don’t need a ton of client-side compute resources to run Ponder, even when operating on large datasets.
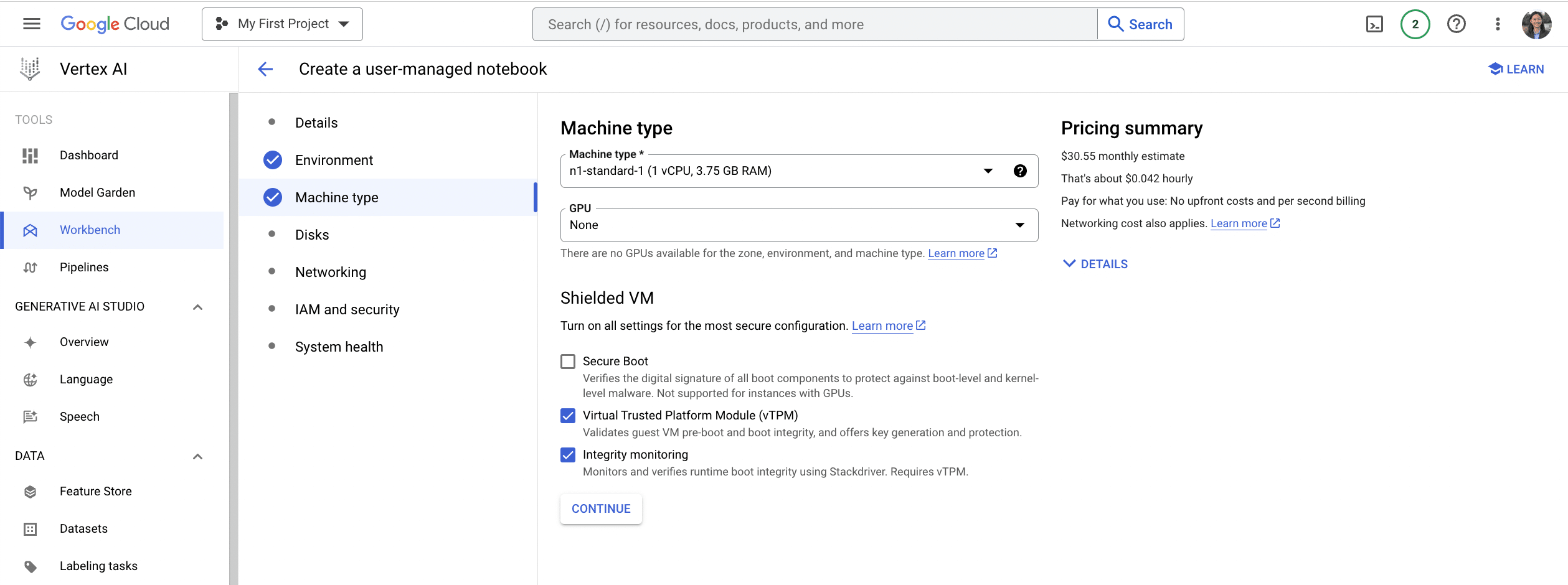
You can use Ponder by simply installing Ponder on your new Vertex notebook environment by running the following command:
! pip install ponder
To get started using Ponder, you first need to initialize Ponder by registering your product key. Your product key can be found in your Account Settings. If you don’t already have a Ponder account, you can create a free account by signing up here.
import ponder
ponder.init(api_key="<Enter-Your-Product-Key-Here>")
Connecting to BigQuery from Vertex AI¶
Ponder lets you run pandas directly in your database, in this case, BigQuery. To do that, we first need to configure a connection to BigQuery using Google Cloud’s Python client for Google BigQuery. Here, in Vertex AI, I load my service account key file stored incredential.jsonand create a BigQueryClientandConnectionobject.
import json
cred = json.loads(open("credential.json").read())
from google.cloud import bigquery
from google.cloud.bigquery import dbapi
from google.oauth2 import service_account
client = bigquery.Client(credentials=service_account.Credentials.from_service_account_info(cred,scopes=["https://www.googleapis.com/auth/bigquery"]))
db_con = dbapi.Connection(client)
Copying a BigQuery Public dataset to your project¶
For the purpose of this example, let’s copy over a dataset from BigQuery Public Dataset into our project to work with. If you already have a dataset in BigQuery that you want to work with, you can skip this step.
! pip install google-cloud-bigquery-datatransfer
from google.cloud import bigquery_datatransfer
transfer_client = bigquery_datatransfer.DataTransferServiceClient()
def copy_bigquery_public_dataset(dataset_id):
# Create new dataset with dataset_id as name
dataset = bigquery.Dataset(f"{cred['project_id']}.{dataset_id}")
dataset.location = "US"
dataset = client.create_dataset(dataset, timeout=30)
# Copy dataset from BigQuery public data into the dataset
destination_project_id = cred["project_id"]
source_project_id = "bigquery-public-data"
transfer_config = bigquery_datatransfer.TransferConfig(
destination_dataset_id=dataset_id,
display_name=dataset_id,
data_source_id="cross_region_copy",
params={
"source_project_id": source_project_id,
"source_dataset_id": dataset_id,
}
)
transfer_config = transfer_client.create_transfer_config(
parent=transfer_client.common_project_path(destination_project_id),
transfer_config=transfer_config,
)
copy_bigquery_public_dataset('fdic_banks')
With Ponder now set up on Vertex AI and a toy dataset now in BigQuery, we are all ready to go!
Working with BigQuery data using pandas dataframes in Vertex AI¶
Traditionally, Python developers working in the Google Cloud ecosystem had two options for loading data from Google BigQuery into a pandas dataframe for analysis, either via BigQuery’s client library and via the pandas library itself. Below we’ll walk you through how you can create a pandas dataframe from your BigQuery data using those different approaches, a couple of things to keep in mind when choosing an approach, and a brief overview of how Ponder is an efficient way to work with pandas in your data warehouse.
Option 1 – Query with BigQuery Client and load to pandas via to_dataframe()
How it Works: The BigQuery client executes your query and the.to_dataframe() operator pulls data out of BigQuery and into a pandas dataframe in your local Python environment.
%%time
query = client.query("SELECT * FROM fdic_banks.institutions")
df = query.to_dataframe()
CPU times: user 410 ms, sys: 104 ms, total: 514 ms Wall time: 3.63 s
df
| fdic_certificate_number | institution_name | state_name | fdic_id | docket | active | address | total_assets | bank_charter_class | change_code_1 | … | csa_name | csa_fips_code | csa_indicator | cbsa_name | cbsa_fips_code | cbsa_metro_flag | cbsa_micro_flag | cbsa_division_name | cbsa_division_fips_code | cbsa_division_flag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 21314 | The First National Bank of Autauga County | Alabama | 14751 | 0 | False | 744 East Main Street | <NA> | N | 223 | … | Montgomery-Selma-Alexander City, AL | 388 | True | Montgomery, AL | 33860 | True | False | None | None | False |
| 1 | 15722 | Baldwin National Bank | Alabama | 9984 | 0 | False | Milwaukee And Ohio Streets | <NA> | N | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 2 | 21103 | State Bank of the Gulf | Alabama | 14586 | 0 | False | West 18th Avenue And Highway 59 | <NA> | NM | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 3 | 21466 | First National Bank of Alabama-Daphne | Alabama | 14846 | 0 | False | 2211 Highway 98 | <NA> | N | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 4 | 19477 | Central Bank of Eufaula | Alabama | 13277 | 0 | False | 223 East Broad Street | <NA> | NM | 223 | … | None | None | False | Eufaula, AL-GA | 21640 | False | True | None | None | False |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 27807 | 20828 | Banco Santander Puerto Rico | Puerto Rico | 14389 | 12675 | False | 207 Ave Ponce De Leon | 5990637 | NM | 223 | … | San Juan-Bayamon, PR | 490 | True | San Juan-Bayamon-Caguas, PR | 41980 | True | False | None | None | False |
| 27808 | 33990 | Bank of St. Croix, Inc. | Virgin Islands Of The U.S. | 55568 | 0 | False | 5025 Anchor Way | 144494 | NM | 221 | … | None | None | <NA> | None | None | <NA> | <NA> | None | None | <NA> |
| 27809 | 33964 | Virgin Islands Community Bank | Virgin Islands Of The U.S. | 55338 | 0 | False | 12 Kings Street | 58087 | NM | 223 | … | None | None | <NA> | None | None | <NA> | <NA> | None | None | <NA> |
| 27810 | 58184 | Merchants Commercial Bank | Virgin Islands Of The U.S. | 441417 | 0 | True | 4608 Tutu Park Mall | 456207 | NM | None | … | None | None | <NA> | None | None | <NA> | <NA> | None | None | <NA> |
| 27811 | 32562 | First Virgin Islands FSB | Virgin Islands Of The U.S. | 45396 | 8449 | False | 50 Kronsprindsens Gade | 56201 | SB | 223 | … | None | None | <NA> | None | None | <NA> | <NA> | None | None | <NA> |
27812 rows × 121 columns
Option 2 – Load table into a pandas dataframe via pandas read_sql()
How it Works: Similarly, pandas uses SQLAlchemy under the hood to execute whatever query you define, pull the results out of your database, and move them into a pandas dataframe.
import pandas as pd
%%time
df = pd.read_sql('SELECT * from fdic_banks.institutions', db_con)
UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy.
CPU times: user 4.82 s, sys: 399 ms, total: 5.22 s Wall time: 7.01 s
df
| fdic_certificate_number | institution_name | state_name | fdic_id | docket | active | address | total_assets | bank_charter_class | change_code_1 | … | csa_name | csa_fips_code | csa_indicator | cbsa_name | cbsa_fips_code | cbsa_metro_flag | cbsa_micro_flag | cbsa_division_name | cbsa_division_fips_code | cbsa_division_flag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 21314 | The First National Bank of Autauga County | Alabama | 14751 | 0 | False | 744 East Main Street | NaN | N | 223 | … | Montgomery-Selma-Alexander City, AL | 388 | True | Montgomery, AL | 33860 | True | False | None | None | False |
| 1 | 15722 | Baldwin National Bank | Alabama | 9984 | 0 | False | Milwaukee And Ohio Streets | NaN | N | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 2 | 21103 | State Bank of the Gulf | Alabama | 14586 | 0 | False | West 18th Avenue And Highway 59 | NaN | NM | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 3 | 21466 | First National Bank of Alabama-Daphne | Alabama | 14846 | 0 | False | 2211 Highway 98 | NaN | N | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 4 | 19477 | Central Bank of Eufaula | Alabama | 13277 | 0 | False | 223 East Broad Street | NaN | NM | 223 | … | None | None | False | Eufaula, AL-GA | 21640 | False | True | None | None | False |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 27807 | 20828 | Banco Santander Puerto Rico | Puerto Rico | 14389 | 12675 | False | 207 Ave Ponce De Leon | 5990637.0 | NM | 223 | … | San Juan-Bayamon, PR | 490 | True | San Juan-Bayamon-Caguas, PR | 41980 | True | False | None | None | False |
| 27808 | 33990 | Bank of St. Croix, Inc. | Virgin Islands Of The U.S. | 55568 | 0 | False | 5025 Anchor Way | 144494.0 | NM | 221 | … | None | None | None | None | None | None | None | None | None | None |
| 27809 | 33964 | Virgin Islands Community Bank | Virgin Islands Of The U.S. | 55338 | 0 | False | 12 Kings Street | 58087.0 | NM | 223 | … | None | None | None | None | None | None | None | None | None | None |
| 27810 | 58184 | Merchants Commercial Bank | Virgin Islands Of The U.S. | 441417 | 0 | True | 4608 Tutu Park Mall | 456207.0 | NM | None | … | None | None | None | None | None | None | None | None | None | None |
| 27811 | 32562 | First Virgin Islands FSB | Virgin Islands Of The U.S. | 45396 | 8449 | False | 50 Kronsprindsens Gade | 56201.0 | SB | 223 | … | None | None | None | None | None | None | None | None | None | None |
27812 rows × 121 columns
Option 3 – Operate on data in BigQuery directly using Ponder’s read_sql()
With Ponder, you can run read_sql on 1TB + BigQuery table even from an 8GB RAM machine in Vertex AI. Instead of pulling data out of BigQuery and into your local memory to convert it into a dataframe, Ponder creates a pointer to a table inside of BigQuery. As you continue your analysis in python, Ponder compiles your subsequent operations on that dataframe from python to SQL and executes them directly inside of your BigQuery instance.
import modin.pandas as pd
%%time
df = pd.read_sql("fdic_banks.institutions",con=db_con)
EarlyAccessWarning: BigQuery support is currently undergoing active development, so certain operations may not yet be fully implemented. Please contact support@ponder.io if you encounter any issues.
CPU times: user 29 ms, sys: 7.24 ms, total: 36.2 ms Wall time: 1.89 s
Here we can see that since Ponder does not pull the table into memory, the read_sql() takes very little time to complete.
df
| fdic_certificate_number | institution_name | state_name | fdic_id | docket | active | address | total_assets | bank_charter_class | change_code_1 | … | csa_name | csa_fips_code | csa_indicator | cbsa_name | cbsa_fips_code | cbsa_metro_flag | cbsa_micro_flag | cbsa_division_name | cbsa_division_fips_code | cbsa_division_flag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 21314 | The First National Bank of Autauga County | Alabama | 14751 | 0 | False | 744 East Main Street | <NA> | N | 223 | … | Montgomery-Selma-Alexander City, AL | 388 | True | Montgomery, AL | 33860 | True | False | None | None | False |
| 1 | 15722 | Baldwin National Bank | Alabama | 9984 | 0 | False | Milwaukee And Ohio Streets | <NA> | N | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 2 | 21103 | State Bank of the Gulf | Alabama | 14586 | 0 | False | West 18th Avenue And Highway 59 | <NA> | NM | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 3 | 21466 | First National Bank of Alabama-Daphne | Alabama | 14846 | 0 | False | 2211 Highway 98 | <NA> | N | 223 | … | Mobile-Daphne-Fairhope, AL | 380 | True | Daphne-Fairhope-Foley, AL | 19300 | True | False | None | None | False |
| 4 | 19477 | Central Bank of Eufaula | Alabama | 13277 | 0 | False | 223 East Broad Street | <NA> | NM | 223 | … | None | None | False | Eufaula, AL-GA | 21640 | False | True | None | None | False |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 27807 | 20828 | Banco Santander Puerto Rico | Puerto Rico | 14389 | 12675 | False | 207 Ave Ponce De Leon | 5990637 | NM | 223 | … | San Juan-Bayamon, PR | 490 | True | San Juan-Bayamon-Caguas, PR | 41980 | True | False | None | None | False |
| 27808 | 33990 | Bank of St. Croix, Inc. | Virgin Islands Of The U.S. | 55568 | 0 | False | 5025 Anchor Way | 144494 | NM | 221 | … | None | None | None | None | None | None | None | None | None | None |
| 27809 | 33964 | Virgin Islands Community Bank | Virgin Islands Of The U.S. | 55338 | 0 | False | 12 Kings Street | 58087 | NM | 223 | … | None | None | None | None | None | None | None | None | None | None |
| 27810 | 58184 | Merchants Commercial Bank | Virgin Islands Of The U.S. | 441417 | 0 | True | 4608 Tutu Park Mall | 456207 | NM | None | … | None | None | None | None | None | None | None | None | None | None |
| 27811 | 32562 | First Virgin Islands FSB | Virgin Islands Of The U.S. | 45396 | 8449 | False | 50 Kronsprindsens Gade | 56201 | SB | 223 | … | None | None | None | None | None | None | None | None | None | None |
27812 rows x 121 columns
Because Ponder can run in a self-contained manner in your python process and takes advantage of BigQuery for all of the compute, you get this scalable pandas capability without having to manage any additional infrastructure.
Ready for something big?¶
When using the first two approaches described, it’s important to keep in mind a couple of constraints:
Your machine’s RAM – As soon as you convert the query results to a pandas dataframe, those results will get pulled out of BigQuery and into your local memory. You’ll need to make sure your local machine (whether that’s your local laptop or a cloud vm) has sufficient memory to handle the amount of data you’re pulling from BigQuery. The rule of thumb before the release of pandas 2.0 has been for RAM capacity to be 5-10x the size of your dataset.
Your development lifecycle – When dealing with large datasets, a common way to workaround the constraints of your RAM capacity is by sampling or aggregating your table in SQL before pulling the results into memory. However, when working in an interactive or exploratory setting, that initial aggregation / sampling can be limiting and inconvenient when working in an iterative manner.
With Ponder, BigQuery users can benefit from the scalability of their warehouse, while using continuing to write Python/Pandas code AND overcoming the challenges listed above.
Now let's put what we've learned to work, let's take a look at what happens when we work with a much larger dataset fda_drug.drug_label which is a 3.19GB dataset.
| Dataset | # of rows | # of columns | Logical Table size (Uncompressed) | Physical Table size (Compressed) |
|---|---|---|---|---|
| fdic_banks.institutions | 27,812 | 121 | 14.81 MB | 2.91 MB |
| fda_drug.drug_label | 119,822 | 89 | 3.19 GB | 554.86 MB |
Again, let’s copy the BigQuery Public dataset to our project.
copy_bigquery_public_dataset('fda_drug')
Remember that our Vertex AI managed notebook is running on a n1-standard-1, which only has 1 CPU and 3.75GB of RAM. So with a 3.19GB dataset, we are reaching the limit of what can actually fit in the memory of this machine.
With Ponder, since the data is not being loaded into the machine, you don't have to worry about this at all! When we do pd.read_sql we are simply initializing the connection to BigQuery. There is no I/O that happens so this only takes 33 seconds!
import modin.pandas as pd
%%time
df = pd.read_sql("fda_drug.drug_label",con=db_con)
EarlyAccessWarning: BigQuery support is currently undergoing active development, so certain operations may not yet be fully implemented. Please contact support@ponder.io if you encounter any issues.
CPU times: user 66.4 ms, sys: 7.42 ms, total: 73.8 ms Wall time: 33.8 s
Now let’s look at what happens when we do the same with pandas.
import pandas as pd
🛑 Be warned that the following command will take a long time to run … and crash your machine. Please save any work on your machine before running this command!
%%time
df = pd.read_sql('SELECT * from fda_drug.drug_label', db_con)
UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy.
Several minutes into this command running, your machine will run out of memory. You will see that your Jupyter notebook kernel on Vertex has died unexpectedly. 😭
So what exactly happened here? Let's go back to our Vertex AI Workbench and click on our notebook. Under "Notebook details", toggle to "Monitoring." We can see that when I ran the pd.read_sql command with pandas, there was a huge spike in the Network traffic meaning that there was significant I/O caused by loading the data into memory locally.
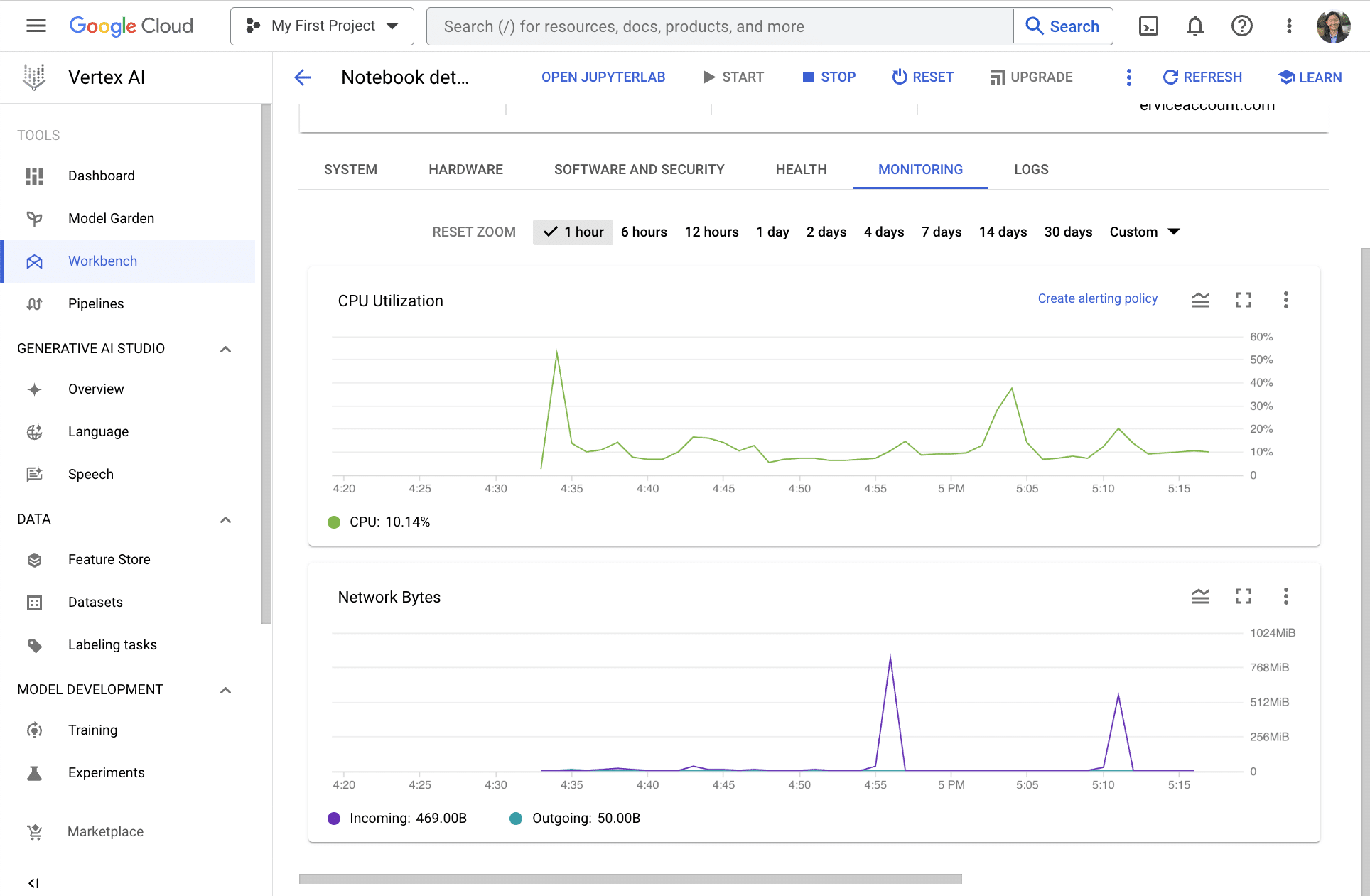
Note that I actually tried to run that command twice, which is why you see two peaks in the purple graph.
Ok, so hopefully, it’s clear now how pandas’s default behavior of pulling your data into memory can be problematic and cause fatal system errors. To go back to using your notebook again, it’s not enought to just simply reload your page — Your kernel is dead now and this is what you will see when you try to reload the page:
Instead, go back to the Vertex AI workbench > Select your notebook > Click on “Reset.” The Reset button wipes the memory content of the VM that you’re running the notebook on and resets the VM back to its initial state.
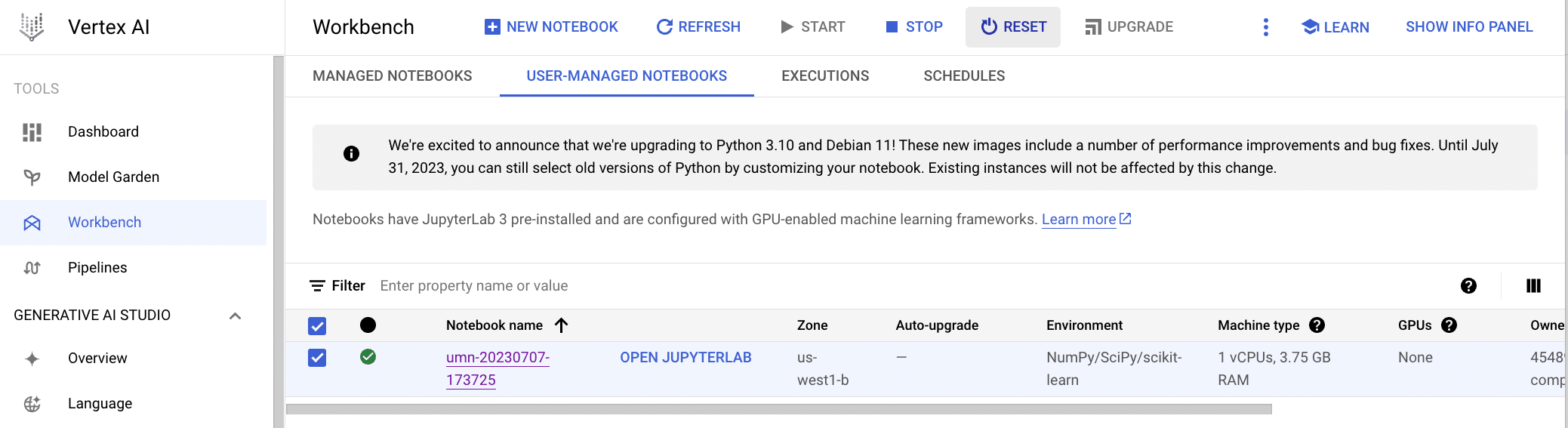
Vertex AI + Ponder: Wrapping it all up¶
In this tutorial, we demonstrated how you can use Ponder to work with pandas efficiently directly on the data in BigQuery. In particular, our demo revealed at least two reasons why you should use Ponder to more effectively leverage your compute resources and avoid fatal errors:
Reason 1: Save on Compute Costs by Lowering Client-side Memory Requirement
Traditionally, practitioners have worked around memory issues in pandas by provisioning “beefy machines” when operating on heavier workloads, but Ponder solves this in a different way: By outsourcing the heavy lifting to your database. This lowers the memory required on your client machine.
This is beneficial for data teams because high-memory machines can be incredibly expensive. See the below chart of the Vertex AI cost for a notebook running on the following machines:
| Machine Type | Monthly estimate | Hourly rate | Usage Pattern |
|---|---|---|---|
| n1-standard-1 (1 vCPUs, 3.75 GB RAM) | \$30.55 | \$0.042 | Instance used for this demo |
| n1-standard-4 (4 vCPUs, 15 GB RAM) | \$110.32 | \$0.151 | Similar specs to a standard laptop |
| n1-standard-32 (32 vCPUs, 120 GB RAM) | \$852.46 | \$1.168 | “Beefy” machine as a data scientist’s workstation |
| n1-standard-96 (96 vCPUs, 360 GB RAM) | \$2,547.58 | \$3.490 | “Beefy” machine for heavy workloads, often shared |
We have seen data teams provision machines with even more memory than the n1-standard 96 just in case pandas runs out of memory and crashes the machine. There is no good empirical way to figure out when pandas would crash for a given dataset size (the rule of thumb is 5-10X your dataset size), so the instance size provisioned is often a result of guessing/trial and error, which leads to wasted resources. In contrast, Ponder lets you opt for the cheaper machine, leading to over 80X in cost savings on the types of instances you have to provision for working with large datasets.
Reason 2: Avoid Fatal Out-of-Memory Errors
As we saw in the demo, pandas out-of-memory errors is fatal and leads to interruptions to service (and possible lost work on the same instance). Given that a “beefy” machine as described earlier can cost thousands of dollars a month, many data teams opt to share the machine across many individuals across the team to save costs. This means that any memory errors can have system-wide impact and lead to disruptions to the team’s work and potentially require IT intervention. With Ponder, you can provision cheaper, isolated instances or even operate on a laptop-scale machine while still being able to operate on large datasets with pandas directly in your data warehouse. No need to worry about out-of-memory errors or provisioning a large instance!
If you’re looking to save costs and avoid disruptive memory error when working with pandas on large dataset, try out Ponder today for free at: https://app.ponder.io/signup
Try Ponder Today
Start running your Python data science workflows in your database within minutes!