

Intro
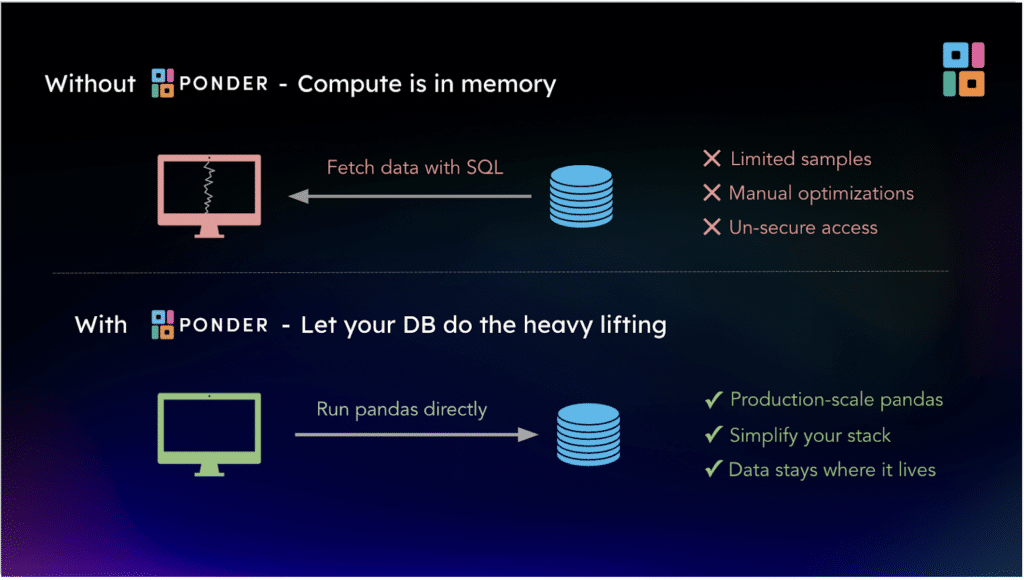
Ponder lets you run pandas code directly in your data warehouse – no cluster management required – and Prefect is one of the most popular data workflow orchestration tools. By combining Ponder and Prefect, data teams can simplify their data stack and accelerate their time to production.
What is Prefect?
Prefect makes it easy for data scientists and data engineers to define, deploy, schedule and monitor data workflows that power BI dashboards and AI/ML applications.
What is Ponder?
Grounded in years of R&D at UC Berkeley and open source Modin, Ponder offers users a high fidelity pandas experience while leveraging your existing database resources for computation. Ponder compiles your pandas code for execution directly in your warehouse.
Ponder gives data teams:
- Production-Ready Pandas: Easily write end-to-end, production-ready pipelines with pandas syntax – no refactor required
- Effortless Scalability: Run those pipelines at +1TB scale without a distributed cluster – just use your Data Warehouse
- Security + Efficiency: Process your data and avoid I/O headaches, because your data never leaves where it lives
Try Ponder Today
Start running pandas and NumPy in your database within minutes!
What makes the Prefect + Ponder combo so powerful?
While practitioners enjoy Prefect’s modularity and ease-of-use, engineers deal with challenges beyond workflow orchestration such as code portability and scalability. As their data volumes grow, teams must refactor code and wrangle with distributed infrastructure (Spark, Dask, Ray) in order to ensure the reliable and timely execution of their pipelines. By combining Ponder and Prefect, data teams can effortlessly write, scale, and manage their data pipelines.
Prefect + Ponder Tutorial
To illustrate how Modin and Prefect can be used together, let’s consider an example data processing workflow using a public loan dataset from Lending Club. Suppose we have this raw financial dataset stored in Google BigQuery, and we want to perform the following processing steps:
- Read the BigQuery data into a pandas dataframe
- Clean the data by removing missing values and dropping unnecessary columns.
- Remove outliers for analytics
- One-Hot Encode categorical features for statistical modeling
- Write the processed dataset into a golden table for model training / inference
Before starting, we need to install + setup Prefect and Ponder.
Install Prefect + Ponder
pip install -U prefect
pip install ponder-v.0.x.whlNOTE: Ponder is in private beta right now. If you’d like early access, feel free to sign up here!
Authenticate
ponder loginOnce you have a Ponder account, you’ll need your Authentication Token from your Ponder Profile in order to follow the login prompts.
Getting Started
To write and scale our loan processing pipeline on BigQuery using Ponder and Prefect, we first replace our vanilla pandas-based code with Ponder’s pandas-based code. This involves importing the Ponder library, authenticating to BigQuery using a service account key, and using the Modin DataFrame class instead of the pandas DataFrame class. Ponder doesn’t store your credentials, it simply uses the database connection to compile + relay your pandas operations for execution directly inside of your warehouse.
For example, to read a BigQuery table, we would initialize Ponder and replace the pandasread_sqlfunction with the Ponderread_sqlfunction as follows:
import ponder.bigquery
import modin.pandas as pd
import os
import json
creds = json.load(open(os.path.expanduser("my_bigquery_key.json")))
bigquery_con = ponder.bigquery.connect(creds, schema="LOANS")
ponder.bigquery.init(con)
df = pd.read_sql("LOANS.ACCEPTED",con=bigquery_con)So what’s the difference between read_sql in pandas vs Ponder?
With pandas, you’re using SQLAlchemy under the hood and reading your entire table into memory. With Ponder, none of your data leaves BigQuery! You can continue to use the pandas syntax but aren’t limited by the available memory in your local environment. Above, “df” is just a pointer to your BigQuery table.
Next, we create a Prefect workflow that defines the loan processing steps and their dependencies. Each processing step is defined as a Python function that takes one or more inputs and returns one or more outputs. To designate any python function as a step in a Prefect workflow or as a workflow itself, it’s as easy as using a task or flow decorator.
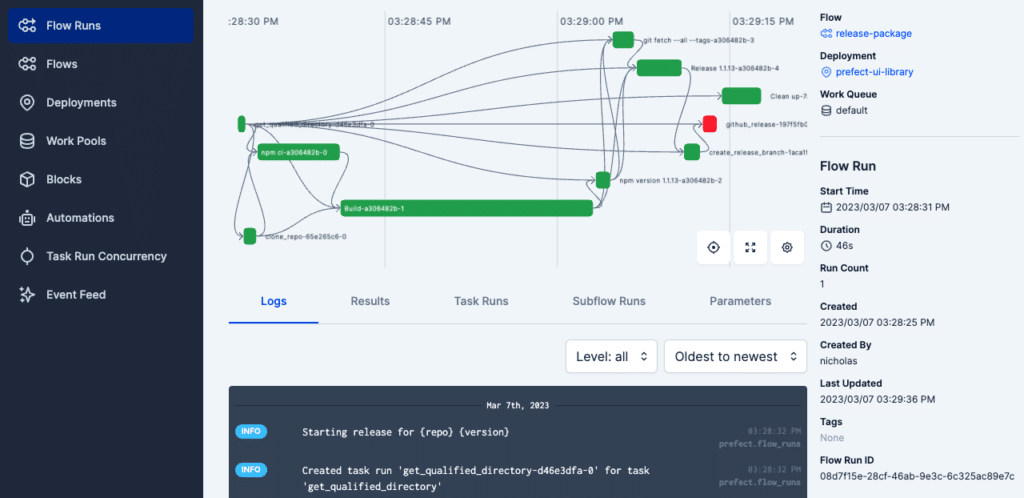
For example, the previous read_sql step would be broken up into initialization and read steps.
from prefect import task
import ponder.bigquery
import modin.pandas as pd
import os
import json
@task(name="Initialize Ponder")
def initialize_ponder(key_path,schema_name):
creds = json.load(open(os.path.expanduser(key_path)))
bigquery_con = ponder.bigquery.connect(creds, schema=schema_name)
return bigquery_con
@task(name="Select GBQ Table(s)")
def data_source_select(tablename, gbq_connection):
# Select Data Source form configured DB
df = pd.read_sql(tablename, con=gbq_connection)
return dfAfter initializing Ponder and selecting our BigQuery data source, we’re ready to clean and transform the raw data. These steps would be defined similarly:
@task(name="Drop Columns w/ Nulls")
def drop_missing_value_columns(df):
# keep columns with at less than 50% null values
keep = df.columns[(((df.isnull().sum() / df.shape[0])) * 100 < 50).values]
return df[keep]@task(name="Outlier Removal Based on Annual Income")
def income_outlier_removal(df):
upper_bound = df.annual_inc.quantile(.95)
lower_bound = df.annual_inc.quantile(.05)
no_outliers = df[(df.annual_inc < upper_bound) & (df.annual_inc > lower_bound)]
print("{} outliers removed".format(df.shape[0]-no_outliers.shape[0]))
return no_outliersTo use categorical features in statistical models, it’s common practice to one-hot encode categorical data. Traditionally, one-hot encoding within a database has been a herculean feat. Databases require users to define a schema upfront, while one-hot encoding generates dummies based on the contents of the table itself. With Ponder this is a trivial task:
@task(name="One Hot Encoding")
def status_dummies(df):
return pd.get_dummies(df,columns="grade")And finally, we can combine all of these tasks into an end to end workflow and persist the results into a golden table for our data science pipeline to pick up for inference or for our data scientists to train new models:
from prefect import flow
@flow(name="Loan Processing Pipeline")
def loan_processing_pipe():
gbqq_con = initialize_ponder("my_bigquery_key.json","LOANS")
ponder.bigquery.init(gbq_con)
df = data_source_select("LOANS.ACCEPTED",gbq_con)
filtered = filter_by_status(df)
selected = feature_selection(filtered)
clean = income_outlier_removal(selected)
final = status_dummies(clean)
persist_gbq_table(final,"LOANS.GOLDENLOANS",gbq_con)Conclusion
In this post, we used Prefect and Ponder to write a loan data processing pipeline to clean up, transform, and persist our Lending Club data. Because we used Ponder in our data pipelines, we were able to:
- Easily write the end-to-end pipeline with pandas syntax
- Effortlessly scale the pipeline by directly using BigQuery’s compute
- Securely process the data, because your data never leaves BigQuery
Now all you have to do is get your pandas code right once, and let the simple + powerful combination of Ponder + Prefect take care of everything else.
Though the example runs on Google BigQuery, Ponder’s technology is database agnostic. Reach out to us if you’d like to try Ponder on Snowflake or whatever other warehouse you’ve got!



