

TLDR: We’ve developed the first-of-its-kind technology that allows anyone to run their pandas code directly in their data warehouse, be it Snowflake, BigQuery, or Redshift. With Ponder, you get the same pandas-native experience that you love, but with the power and scalability of cloud-native data warehouses.
From day one, our mission at Ponder has been to radically improve the productivity of data scientists by empowering data science at scale, while preserving the ease of use and flexibility you get with the pandas API. Today, we’re kicking this mission up a notch. We’re excited to share how we are able to support data scientists to run pandas at scale directly in your data warehouse of choice!
If you are interested in trying this new capability out, sign up here!
Try Ponder Today
Start running your Python data science workflows in your database within minutes!
The Missing Link: Data Warehouses and Pandas
We firmly believe that data scientists shouldn’t need to know where or how their workloads are run, just that they get to use their favorite one-stop-shop for data science, pandas. This ethos is the foundation of Ponder, dating back to the inception of our open-source project, Modin, whose vision was to enable data scientists to run pandas anywhere at scale, be it your laptop, cluster, or on the cloud. We made considerable progress on this vision, with Modin reaching more than 5M downloads.
Meanwhile, on the analytics side, data teams in every organization have made heavy investments in relational databases and data warehouses. Databases have been battle tested for many decades and come with an unbeatable combination of performance, reliability, and security guarantees. It is no wonder that more and more data is moving to cloud data warehouses, and that user confidence in these platforms is continuing to rise.
So we had this wild idea:
What if we could enable users to employ the pandas API directly on their data warehouse?
Having authored the foundational theory on dataframes, we knew how challenging of a feat this would be. SQL and Python have traditionally lived in two different worlds: the worlds of data analytics and data science, respectively. If you wanted to use pandas with data in your data warehouse, you would need to pull the dataset into the memory of your machine, most likely a laptop!
This means that you are limited to working with the amount of data that can comfortably fit on your machine. Even if you are able to export a large amount of data out of your data warehouse, pandas is simply not very scalable on large datasets.
Naturally, these issues lead to slow development velocity and present roadblocks for data teams that need to operate on data at scale. For IT teams, access control and security is a nightmare if your data team relies on pulling sensitive data out of your warehouse to their laptops to test out their latest models or experiment with their analyses.
Some data teams might opt to abandon pandas altogether, resorting to crafting unwieldy SQL queries to reimplement stuff that has already been done in pandas. While SQL is a great language, trying to do something like one-hot encoding to transform features in SQL is like trying to fit a square peg in a round hole.
There are many reasons why data scientists prefer pandas. It’s:
than SQL for data science needs
Data Warehouses, meet Pandas
Our team at Ponder has been working hard to develop a breakthrough capability that lets you run pandas directly in your data warehouse. Before we dive deeper, let’s take a look at what this experience looks like:
Pandas on a Terabyte
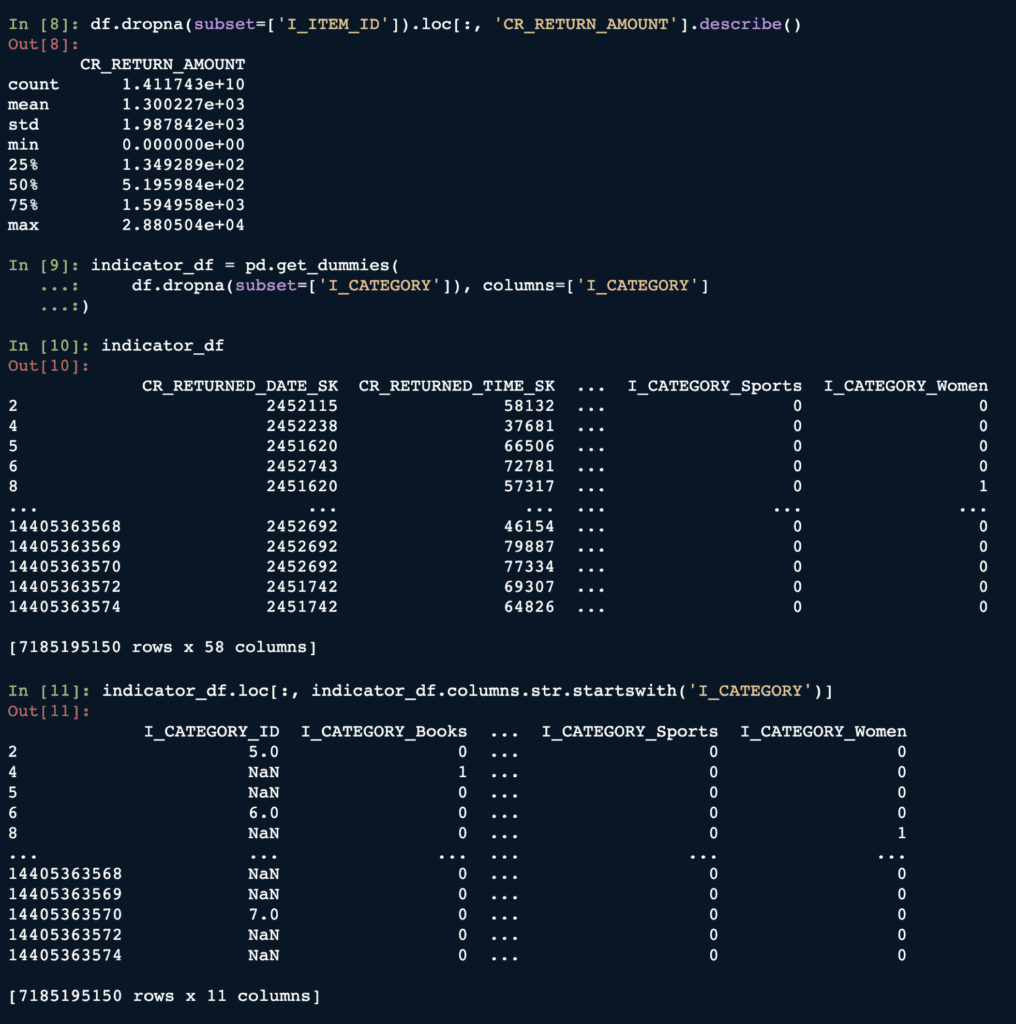
Here is a pretty standard workflow where we are working with a dataset using pandas: dropping nulls viadropna, printing out the summary statistics viadescribe, getting one-hot encoding of a categorical column viaget_dummies(a common feature engineering step), and more.
OK, so this looks like your plain old pandas. But let’s print out the dataframe and look closer.
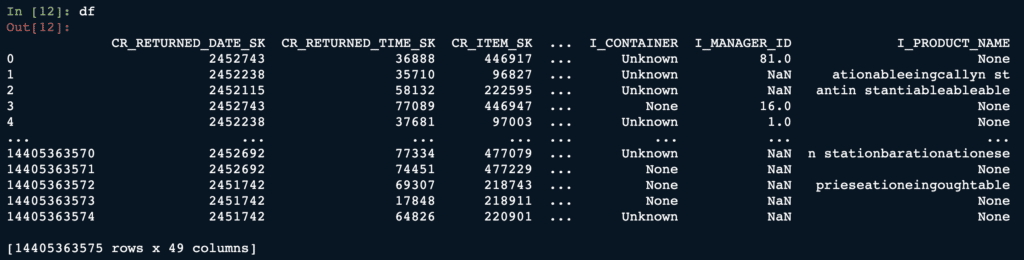
We can see that the dataframe we’ve been working with contains more than 14 billion rows!
So this is pandas running on 1TB of data! 🤯
And if that’s not enough, what if we told you that every single pandas call we saw earlier was actually running inside of Snowflake!
Yes, you read it right — this is not data stored in a CSV, a Parquet file, or in memory. It’s actually running directly INSIDE of a data warehouse!
And it’s running pandas on a terabyte of data in your warehouse — way bigger than what your laptop/workstation memory can handle. At the same time, the pandas user experience stays exactly the same — except that it’s way faster, way more scalable, and way more reliable.
With Ponder, your data never leaves your data warehouse. It gets executed directly IN the warehouse, meaning that we inherit all the scalability and security benefits of the database, while still preserving the ease-of-use, flexibility, and power of pandas.
Pandas ❤️ data warehouses — a match made in heaven! You can work directly with pandas to get scalable insights and build AI models. You can iterate on your pandas workflows quickly, and nothing changes when you go from prototype to deployment. You supercharge your development cycles with lightning-fast, interactive results on your entire dataset.
With our new pandas-in-DB technology, you get the best of both worlds: a fully pandas-native experience that is familiar and fast to prototype, plus the scalability and security benefits of operating in a data warehouse.
If this is interesting to you, sign up here to try Ponder today!
Try Ponder Today
Start running your Python data science workflows in your database within minutes!
We’re incredibly excited to see what you can do with this technology.
Check out a 5-minute demo of Ponder in action here!



