

DuckDB recently introduced support for the PIVOT operator. Pivot is a common data transformation that reshapes your table along a specified index or column. It is commonly used for reporting and analysis in spreadsheets, databases, and working with dataframes.
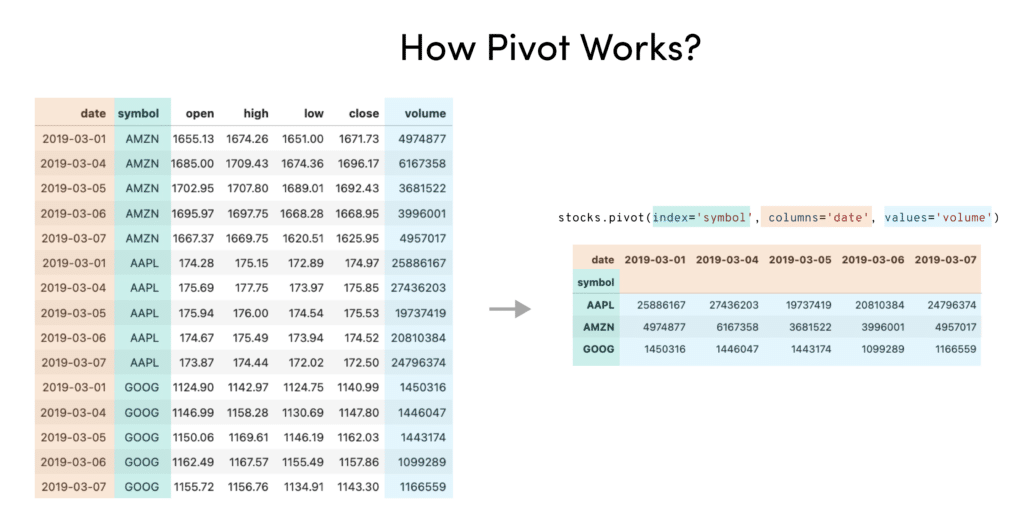
Given how useful pivot is for working with data, we at Ponder couldn’t wait to try out the new DuckDB PIVOT. In this post, we compare the syntax for pivoting with DuckDB, Snowflake, and Ponder (which uses the pandas API).
DuckDB Pivot
This is the DuckDB query run through a popular database application called DBeaver, which provides a convenient interface for working with lots of different databases. We’re running this, and all of our examples, on a small subset of the TPCH database.
SELECT PONDER_ROW_NUMBER AS C_MKTSEGMENT,
AUTOMOBILE AS "AUTOMOBILE",
BUILDING AS "BUILDING",
FURNITURE AS "FURNITURE",
HOUSEHOLD AS "HOUSEHOLD",
MACHINERY AS "MACHINERY"
FROM (PIVOT
(SELECT "C_CUSTKEY", "C_NAME", "C_ADDRESS", "C_NATIONKEY", "C_PHONE", "C_ACCTBAL", "C_MKTSEGMENT", "C_COMMENT", rowid AS "PONDER_ROW_NUMBER",
FROM CUSTOMER
ORDER BY C_ACCTBAL) ON "C_MKTSEGMENT" USING MIN("C_ACCTBAL"))
ORDER BY C_MKTSEGMENT;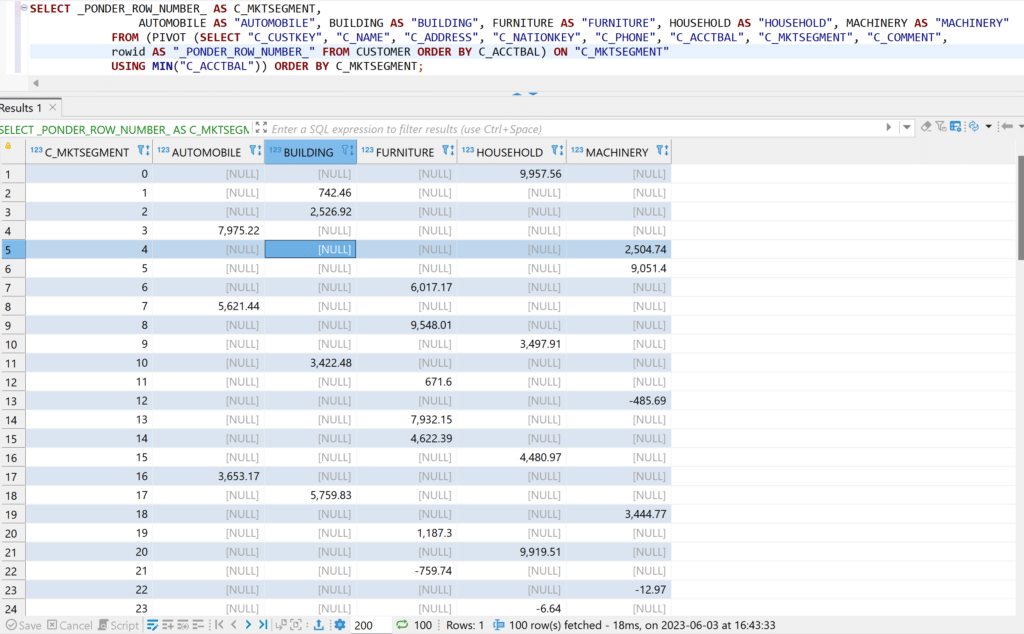
This looks pretty nice. The C_MKTSEGMENT column is just an artificial column added to match pandas’s semantics of having a row number associated with dataframe rows.
How DuckDB Compares to Snowflake
Now let’s try this out on Snowflake, using the same syntax as DuckDB above:
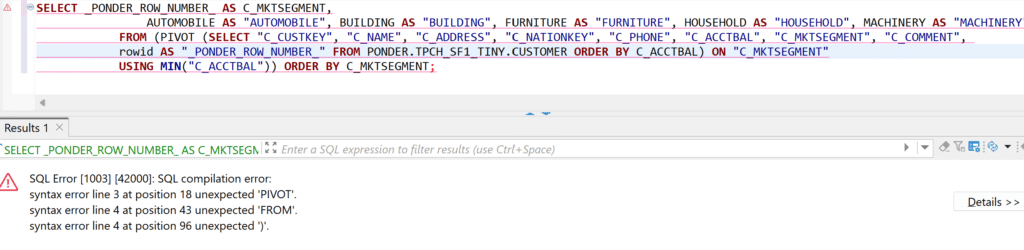
Uh-oh — What happened here? It turns out that the DuckDB Pivot syntax is very different from Snowflake’s. Let’s try rewrite this in the Snowflake SQL dialect:
SELECT "C_MKTSEGMENT",
"C_MKTSEGMENT" AS PONDER_ROW_NUMBER,
"AUTOMOBILE" AS "AUTOMOBILE",
"BUILDING" AS "BUILDING",
"FURNITURE" AS "FURNITURE",
"HOUSEHOLD" AS "HOUSEHOLD",
"MACHINERY" AS "MACHINERY"
FROM
(WITH PONDER_PIVOT_GB AS
(SELECT "C_ACCTBAL",
ROW_NUMBER() OVER (
ORDER BY 1) AS PONDER_ROW_NUMBER,
"C_MKTSEGMENT"
FROM
(SELECT "C_CUSTKEY",
"C_NAME",
"C_ADDRESS",
"C_NATIONKEY",
"C_PHONE",
"C_ACCTBAL",
"C_MKTSEGMENT",
"C_COMMENT"
FROM PONDER.TPCH_SF1_TINY.CUSTOMER)) SELECT *
FROM PONDER_PIVOT_GB PIVOT(MIN("C_ACCTBAL")
FOR "C_MKTSEGMENT" in ('AUTOMOBILE', 'BUILDING', 'FURNITURE', 'HOUSEHOLD', 'MACHINERY')) AS P("C_MKTSEGMENT", "AUTOMOBILE", "BUILDING", "FURNITURE", "HOUSEHOLD", "MACHINERY"));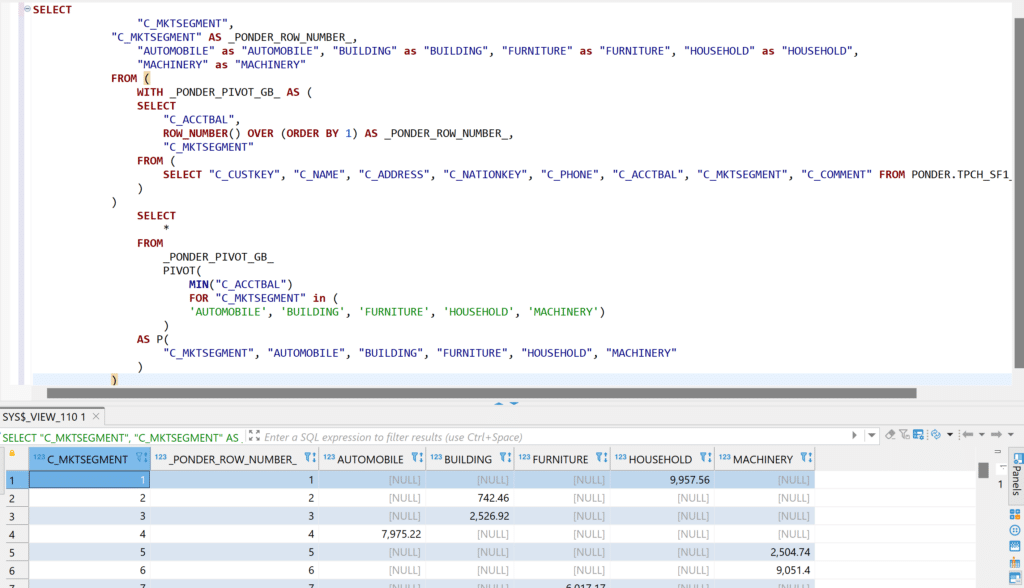
Everything’s as it should be. Now let’s try this operation with Ponder.
How Pivoting with Ponder Differs from DuckDB Pivot and Snowflake Pivot
With Ponder, you can write your code in pandas. Ponder automatically translates your code to SQL queries that run on your database. You don’t have to work with a single line of SQL to work with the data in your database.
Pivoting with Ponder on DuckDB
First, we connect to the CUSTOMER table using read_sql.
As we can see, pandas’s pivot method is much more succinct and flexible than writing SQL queries. The pivot operation itself is just a single line of code!
df_duckdb.pivot(columns='C_MKTSEGMENT', values='C_ACCTBAL')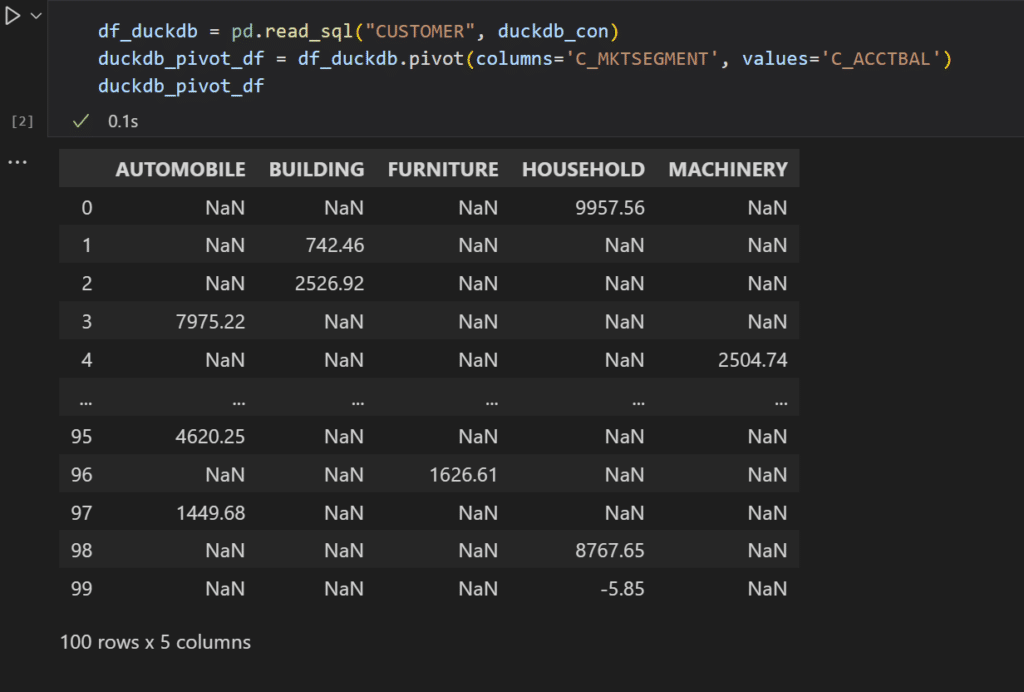
Pivoting with Ponder on Snowflake
Even better, with Ponder, switching from working with data in DuckDB to working with data in Snowflake is as easy as changing your connection. The rest of your code stays the same, so you don’t have to rewrite from one dialect of SQL to another.
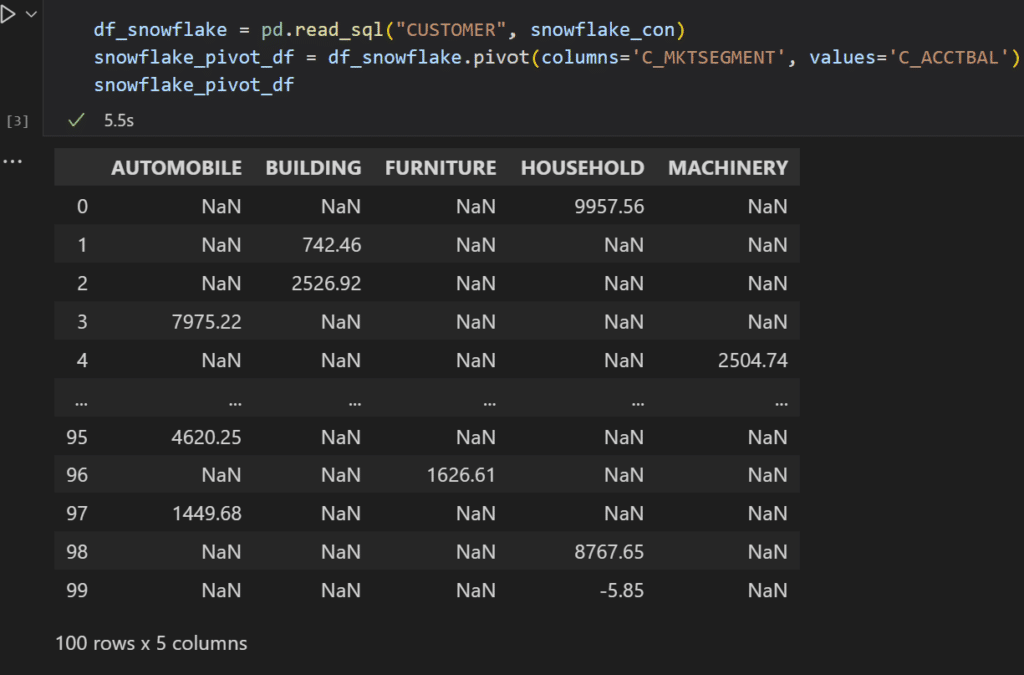
To run this on Snowflake, we used the same lines of code — and it’s the same pandas code with used with DuckDB. Ponder is completely infrastructure-agnostic so that you have the freedom and flexibility to pick the infrastructure backend that works best for you.
DuckDB Pivot, Snowflake Pivot, and Ponder
Ponder translates your pandas code to SQL for you and runs that SQL query in your data warehouse. Don’t worry if the DuckDB Pivot syntax is different from Snowflake’s, or different from BigQuery’s. Let Ponder take care of those idiosyncrasies for you. With Ponder, switching to working with data in a different database is as easy as changing your connection.
Try Ponder Today
Start running your Python data science workflows in your database within minutes!



