

tl;dr: Ponder lets you run your Python data workflows (in pandas or NumPy) securely, seamlessly, and scalably in your data warehouse or database, and as of today, anyone can try Ponder for free. Get started in less than 5 minutes by going to https://app.ponder.io/signup.
How data work is done today
Data work is done today using Python libraries like pandas — the #1 most popular data science library, used by one in four developers — because it’s easy-to-use, flexible, and convenient. But since pandas was designed to operate in-memory, once you start working with medium-to-large datasets, it quickly grinds to a halt and you run into out-of-memory issues.
So what do data teams do? They rewrite their data pipelines in a big data framework like Spark or SQL, which is a painful, error-prone process that can take weeks to months, or they use other so-called dataframe APIs like PySpark, the pandas API on Spark, Ibis, and Snowpark. But since these libraries don’t match the pandas API and behavior as-is, they’re back to square one of having to rewrite their data pipelines using a whole new language that is less flexible and expressive — and less familiar — than pandas.
How Ponder is changing the status quo
Ponder’s mission is to improve user productivity without changing their workflows, and we do this by letting you run pandas, at scale and securely, directly in your data warehouse or database.
It shouldn’t matter whether your data is small, medium, or large: the same data pipelines should run as-is, without any additional effort from the user.
Just pip install Ponder and try it yourself!
Run pandas and NumPy on DuckDB within minutes!
How does this work?
By design, the Ponder experience is virtually indistinguishable from the pandas experience: Ponder uses the pandas API and preserves the same dataframe semantics (aka behavior) that make pandas so easy to use and popular.
But under the hood, the two are very different — Instead of working with an in-memory pandas dataframe, Ponder translates your pandas code to SQL that can be understood by your data warehouse. The effect is that you get to use your favorite pandas API, but your data pipelines run on one of the most battle-tested and heavily-optimized data infrastructures today — databases.
To make this concrete, let’s look at how a pandas command like read_sql works with Ponder. With vanilla pandas, read_sql pulls your data from your database into memory. With Ponder, read_sql simply establishes a connection to your table in your data warehouse. Data stays in your warehouse and any subsequent pandas commands you run get executed as SQL queries in your warehouse.
Here’s an example of Ponder in action — after importing + initializing Ponder and connecting to Snowflake, you just use pandas as normal: the operations after read_sql all get “pushed down” as SQL to the data warehouse, with no additional effort from the user.
import ponder
import modin.pandas as pd # Open-Source Modin acts as Pandas orchestrator
ponder.init()
import snowflake.connector
db_con = snowflake.connector.connect(user=**, password=**, account=**, role=**, database=**, schema=**, warehouse=**)
df = pd.read_sql("DB_TABLE",db_con)
# Run operations in pandas - all in Snowflake!
df.describe() # Compute summary statistics
x = df.select_dtypes(include='number').columns
(df[x] - df[x].mean())/df[x].std() # Z-score normalization
pd.get_dummies(df, columns="language_code") # One-hot encodingWhy does this matter?
By running everything directly in the database, Ponder tackles a number of key problems preventing data science projects from reaching fruition: speed, efficiency, cost, security, and productivity.
Ponder is:
- Seamless — no manual translation necessary: Ponder uses the pandas API and matches the pandas UX, so you can skip weeks to months of manual translation to some other big data framework to run data pipelines at scale and just use pandas throughout.
- System-agnostic — no more lock-in: Ponder works with multiple backends, but users can continue to use vanilla pandas, so switching data warehouses is just as easy as changing your connection string.
- Scalable — no more pandas-at-scale problems: pandas can be slow and inefficient, and worse, crash thanks to out-of-memory errors. All of these problems go away with a scalable database or data warehouse backend.
- Serverless — no additional infrastructure necessary: A common approach to address pandas scalability issues is to throw more cores and beefier machines at the problem by provisioning a separate Spark, Ray, or Dask cluster. This adds unnecessary infrastructure complexity. No longer: Ponder will use your existing data warehouse.
- Secure — no data leaves the premises: Users commonly export data out of their data warehouse to operate on it in pandas; now data can stay where it is, with pandas code being “pushed” to the data. With Ponder, you can now securely perform data science on data, all in your warehouse.
Supported Data Infrastructures

As part of our public beta launch, we support pandas on Snowflake and DuckDB, and have initial BigQuery support. DuckDB is an excellent choice for small-to-medium size datasets or for those who don’t have a default data warehouse, while Snowflake and BigQuery are great choices for those preferring a cloud-native, arbitrarily scalable data warehouse. We are also continually adding other databases and data warehouses; on our list include Redshift, Synapse, Postgres, etc. If there’s a database or data warehouse you think we should be supporting ASAP, let us know at support@ponder.io.
Show me the Numbers!
You may be wondering: How well does Ponder do on supporting pandas at the small, medium, and large scales? To test that, we present some benchmark numbers for Ponder on DuckDB (targeting the small and medium case), and Ponder on Snowflake (to target the big data case), on some common pandas operations (read_csv, resample, groupby).
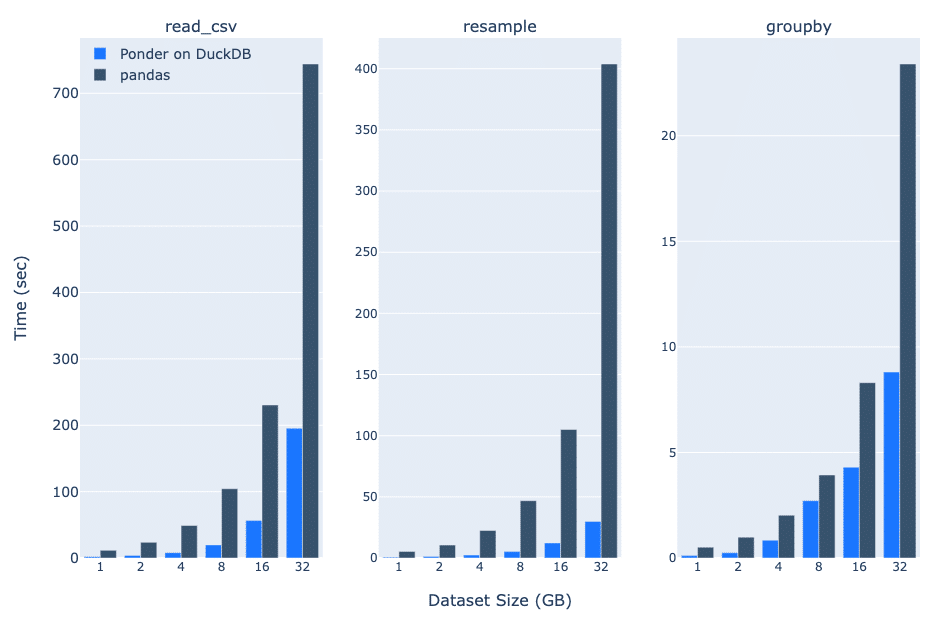
As we can see, Ponder on DuckDB is significantly faster than vanilla pandas for each of these operations even at the 1 GB dataset size, and the difference increases as we scale to 32 GBs. At 32 GBs, Ponder on DuckDB is ~4X as fast for read_csv, ~14X for resample, and ~3X for groupby.
To make this concrete: With vanilla pandas, resample on 32GB of data takes more than 6 minutes. With Ponder on DuckDB, it takes just under 30 seconds.
The Ponder on Snowflake benchmark numbers are on a 150M row dataset running on a Snowflake Large warehouse. You can find the video of the end-to-end workflow of Ponder running on Snowflake here.
Note that these results are run on pandas version 1.5.3, stay tuned for the benchmark for pandas 2.0 coming soon!
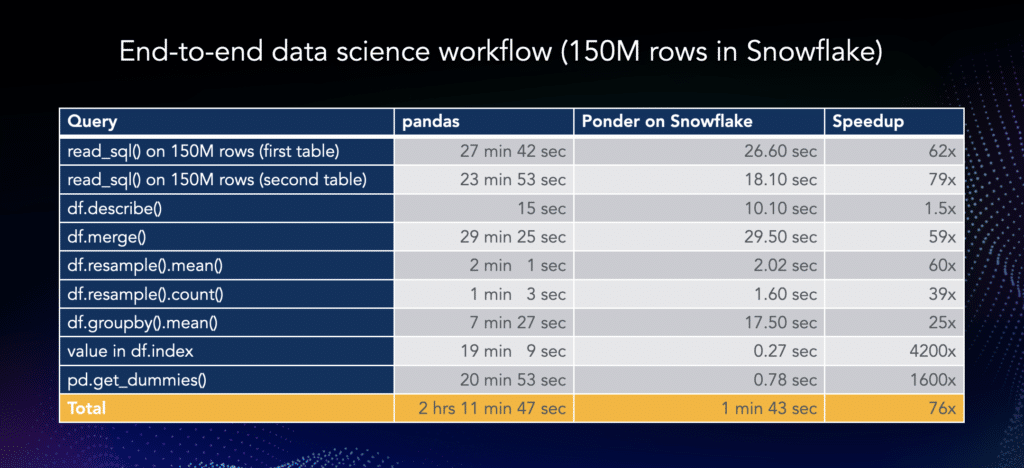
Overall, Ponder on Snowflake is 76x faster than pandas, and it occupies almost no memory on your machine!
Conclusion
With Ponder, you can continue developing data science pipelines or analyzing your data using your familiar library, pandas, but now with the reliability, scale, and security of a data warehouse. Ponder is infrastructure-agnostic, so switching databases — say, from Snowflake to BigQuery — is as simple as swapping the connector, with the rest of the code staying entirely as-is.
Get Started for Free Today!
You can start running your Python data workflows in your data warehouse in three easy steps! Check out the video here to get started in 5 minutes!
- Create an account here.
Install Ponder on your machine:
pip install ponder- Connect to a database and start running your Python data workflows in your warehouse! Check out our quickstart guide for more info.



