

On Nov. 16th, 2022, Alejandro Herrera (Solution Architect) and Rehan Durrani (Founding Engineer) spoke to UCSD Professor Arun Kumar’s “Systems for Scalable Analytics” class. Below are 10 takeaways about the Modin story — The challenges introduced by the fact that Pandas doesn’t scale well, the ways Modin solves these challenges, and Ponder’s vision for a “Pandas on everything” future where you can use Modin to make the Pandas API work with any backend (Ray, Dask, Snowflake, Postgres, etc.). Full recording available here.
1. People love Pandas, but Pandas doesn’t scale
People love Pandas — it’s downloaded more than 20 million times a week — because it’s flexible (600+ APIs), it’s great for prototyping, it’s easy-to-use, and it’s widely adopted so has a well-developed ecosystem (good Stack Overflow documentation, etc.).
But Pandas is single-threaded and doesn’t manage memory efficiently, so it doesn’t scale well. To learn more about why, see this article from Ponder Co-Founders Devin Petersohn and Aditya Parameswaran.

2. Prototyping and scaling with different tools slows development
The result is that while people love prototyping in Pandas, they often have to turn to other tools to scale to production-size datasets. This data stack fragmentation introduces lots of problems (time spent rewriting code, coordination issues across teams, etc.), which slows development.
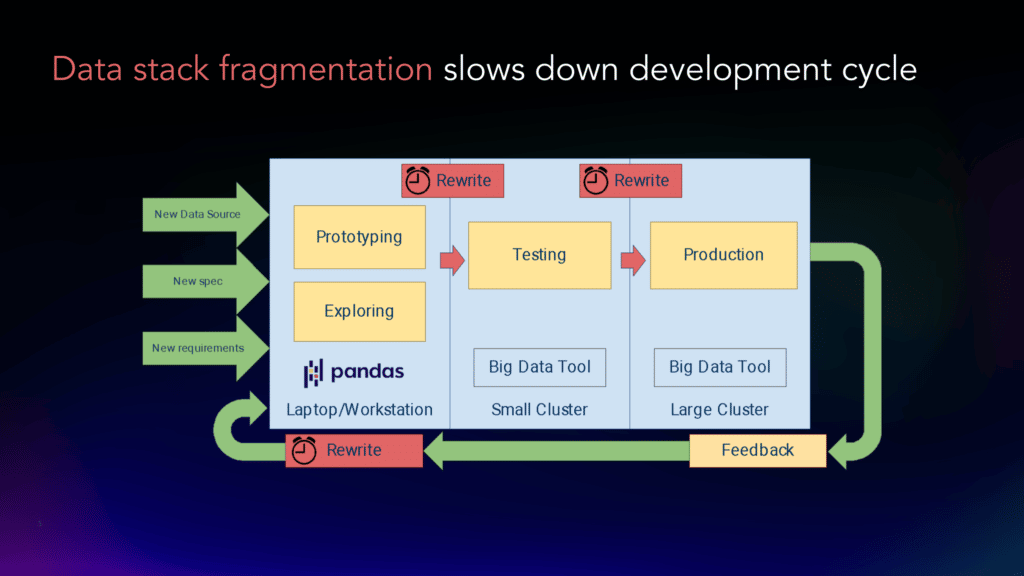
3. Modin bridges this prototype-to-production gap
Modin is a scalable drop-in replacement for Pandas, which means it’s designed to behave exactly like Pandas (it uses the same API, and throws the same errors, etc.), but unlike Pandas, it’s distributed. This gives you the ease-of-use of Pandas, but the scalability of big data frameworks.
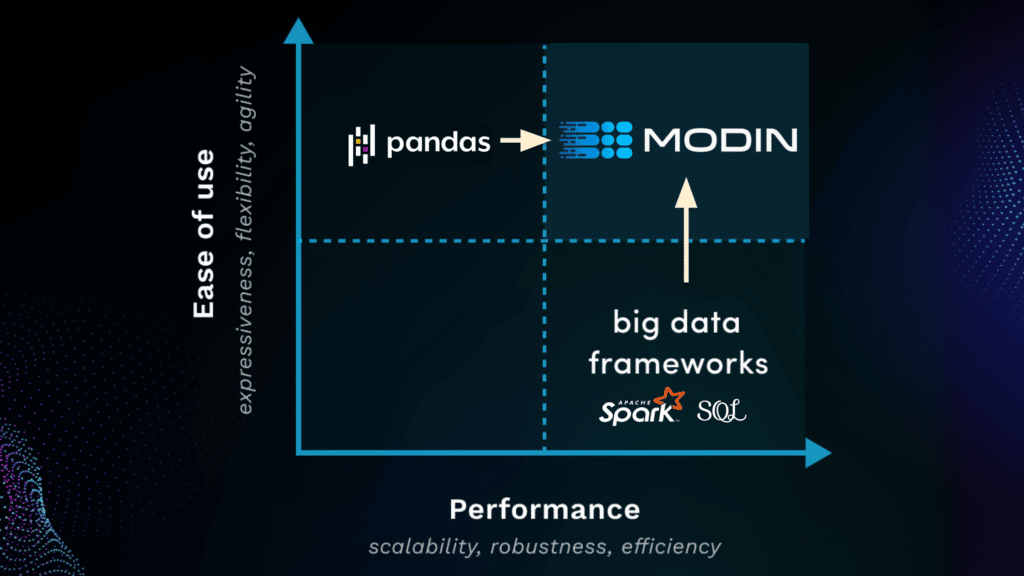
4. To understand Modin, we have to understand DataFrames
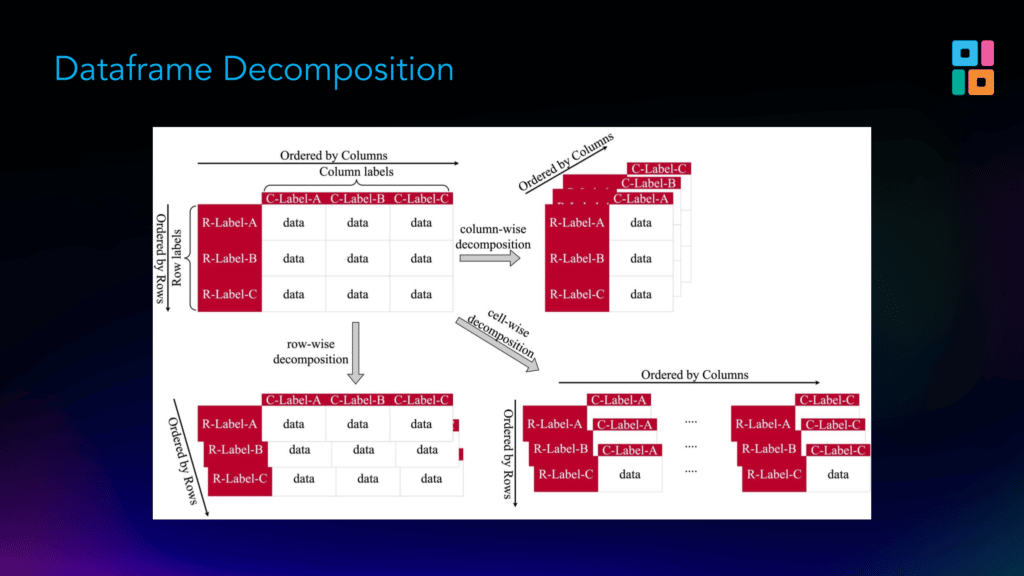
DataFrames are arrays of data with column labels, row labels, and schemas. This structure makes them very flexible.

5. Scaling Pandas DataFrames presents three main challenges
Pandas DataFrames are hard to scale for several reasons: With 600+ functions / 240+ operators, the Pandas API is massive, which makes it hard to optimize by hand; there are row-wise operations, column-wise operations, etc., so you have to use different approaches to parallelization depending on the function; and SQL databases are usually tall and skinny (few columns and many rows), but since DataFrames can transpose tall and skinny tables, you can also have many columns and few rows!
6. Modin’s partitioning strategy varies based on the function it’s parallelizing
One of the ways Modin tackles these challenges (the parallel execution one in particular) is to split up DataFrames into different kinds of chunks depending on the function it’s trying to parallelize, a process called partitioning. For some functions, the right way to parallelize them is to break DataFrames into columns; for others, into rows; and for others, into blocks / cells.
7. Modin modifies metadata only when necessary
Another technique Modin uses to efficiently parallelize the Pandas API is to recognize when it needs to modify metadata (type, position, order), and when it doesn’t. As an example, let’s consider how position is affected when you do the following:
- filter your DataFrame (pulling out particular rows or columns)
- perform the .apply() function three times
- extract a particular element using .iloc()
In this case, only the filter and the .iloc() calls affect the resulting position, and .apply() doesn’t require the position as an input, so naively recalculating position metadata after each operation would be wasteful. Instead, Modin defers this calculation until it’s necessary, which in this case means recalculating only once after the three .apply() calls and .iloc().
8. Modin decomposes the 240+ Pandas operators into 16
Pandas has hundreds of operators, but Modin decomposes these down to 16 across three categories: low-level operators (map, explode, groupby, reduce), metadata operators (infer_types, filter_by_types, to_labels, from_labels, transpose), and relational operators (mask, filter, window, sort, join, rename, concat). The 16 Modin operators form a complete set, so although not every Pandas operator has been implemented in Modin yet, all can be. (Modin already provides native coverage for 90+% of the Pandas API, and falls back to Pandas for the rest.)
For more on each of these operators, see here.
9. Modin was designed to be modular
Modin has four layers: The topmost layer is the API layer (Pandas, etc.). The second layer is the query compiler layer, which translates from the API layer down to the core set of 16 algebra operators. The third layer is where the core operators do their data manipulation. And the fourth layer is the execution engine layer.
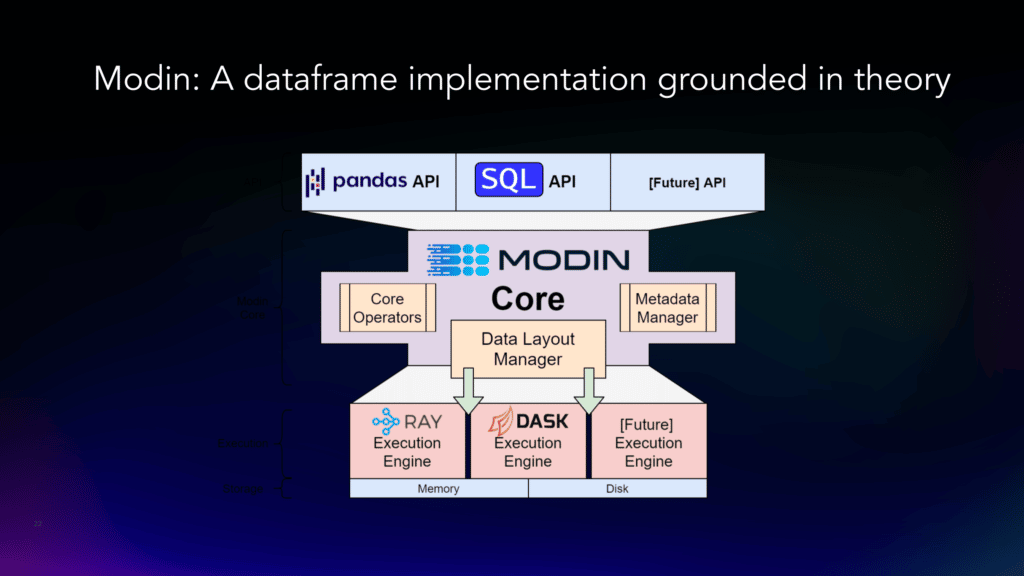
10. Modin is the key to Ponder’s “Pandas on Everything” vision
Ponder envisions a “Pandas on Everything” future, where we can use the Pandas API, but scale it using Modin + whatever backend we want: Ray, Dask, Snowflake, Postgres, etc. We strongly believe that you shouldn’t need to stop using the tools you love, like Pandas, in order to get production-grade scalability.

Conclusion
Many people know and love Pandas, but Pandas doesn’t scale well. Modin is a scalable drop-in replacement for Pandas that gives you the ease of Pandas, with the scalability of a big data framework, thus bridging the prototype-to-production gap.
Ponder is working towards a “Pandas on Everything” future where you can use Modin to make the Pandas API work with any backend (Ray, Dask, Snowflake, Postgres, etc.). If you’re interested in trying out what we’re building, sign up here!
To get started with Modin today, check out the Modin “Quick Start” guide. And make sure to follow Ponder on Twitter and LinkedIn stay up-to-date on all things Scalable Pandas.
Note: Featured photo of panda climbing tree by Chester Ho on Unsplash.



