

In our latest release, Ponder 0.2.0, we are thrilled to announce the public beta of BigQuery support, which makes Python data science work on BigQuery easier than ever. You can now harness the capabilities of BigQuery directly within your pandas workflows, eliminating the need for data movement, so that you can enjoy the scalability and governance provided by an enterprise-grade data warehouse.
Get started today by installing the BigQuery distribution from our latest release:
pip install ponder[bigquery]Why Use Ponder for Your BigQuery Python Work?
Pandas is great for data cleaning, transformation, feature engineering and exploration — it is the first tool people reach to when they want to do anything data science or ML-related. But today, the only way to use pandas with BigQuery is to pull your data out of the warehouse to process it in memory. This can lead to fatal out-of-memory issues even when working on several GBs of data, as we showed in this article.
Ponder addresses this challenge by automatically translating your pandas code into SQL so that it runs directly on BigQuery. This not only alleviates the challenges related to in-memory processing, but also unleashes the full potential of BigQuery’s powerful serverless compute capabilities for your data workflows. You get the scalability of an enterprise-grade data warehouse, without the headache of having to provision and manage a separate compute infrastructure to run your Python code. Let BigQuery handle all the heavy lifting!
Now let’s take a look at what we can do with Ponder on BigQuery.
Try Ponder Today
Start running your Python data science workflows in your database within minutes!
High-fidelity Pandas Experience
At Ponder, we strive to preserve the full-fidelity pandas experience and the pandas API so that no code changes are required when you move from pandas to Ponder. Since we put out the early access on BigQuery, our team has been hard at work to broaden the functional coverage for a wide range of pandas APIs on BigQuery. With our latest release, we have reached a level of functional coverage that matches our other public-beta-ready backends, including Snowflake and DuckDB. For a full list of our supported APIs, check out our documentation here.
Now, let’s explore some examples of what you can do to run BigQuery Python work with Ponder. You can check out the full notebook example here or try it out on Colab!
![]()
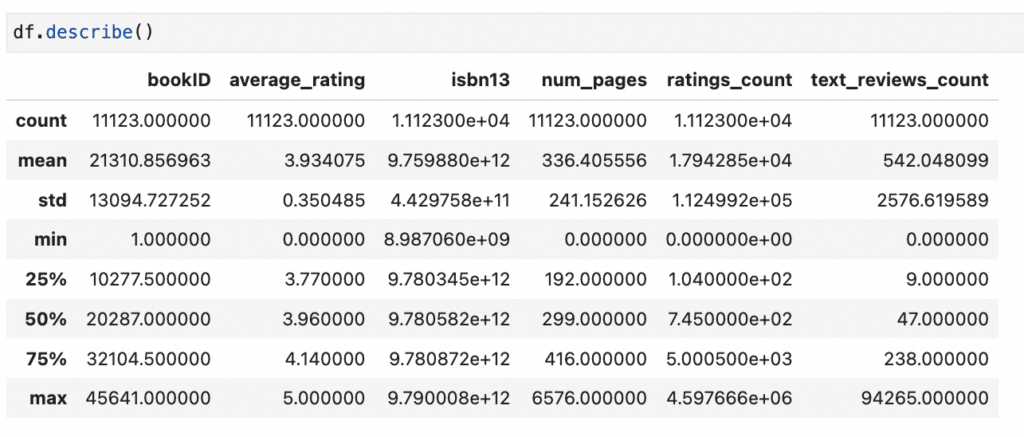
Here, we are working with the Goodreads dataset from Kaggle, which contains books and their review information. We can print out basic statistics to get an overview of the numerical columns in the dataset.
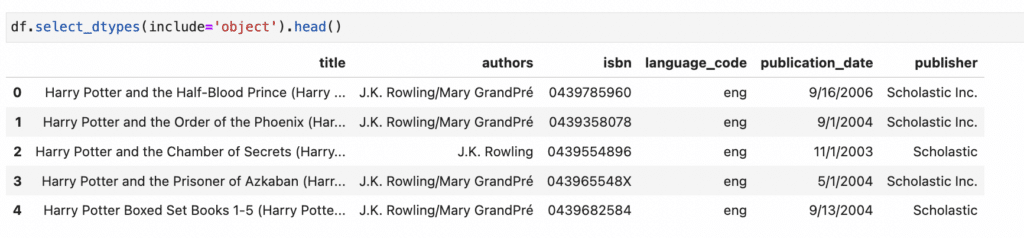
Even though data types in BigQuery can be quite different than Pandas dtypes, Ponder lets you continue to work with pandas data types and filter to columns that are “object” types.
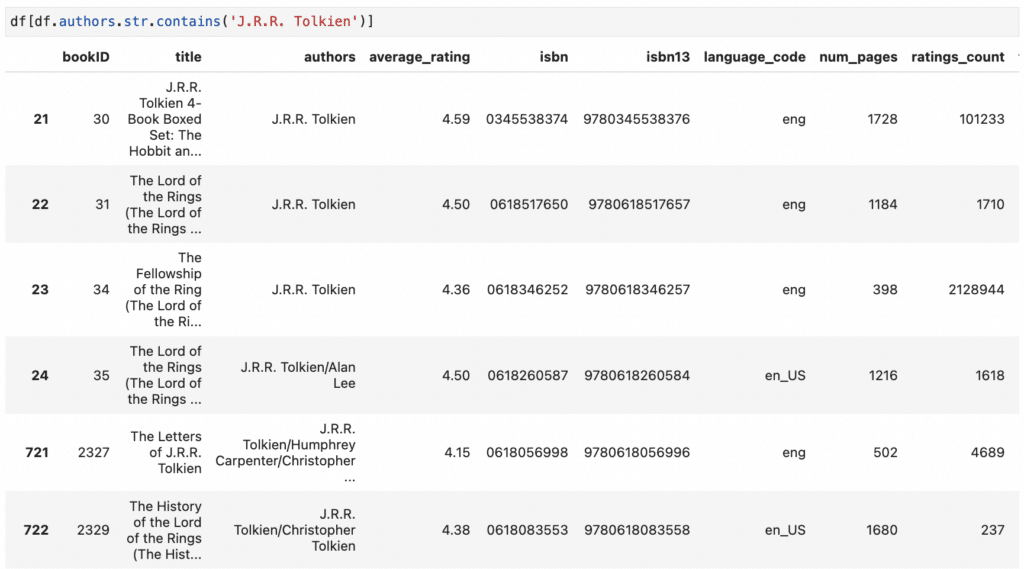
We can easily work with string value columns. For example, let’s look at all the books written by J.R.R Tolkien.
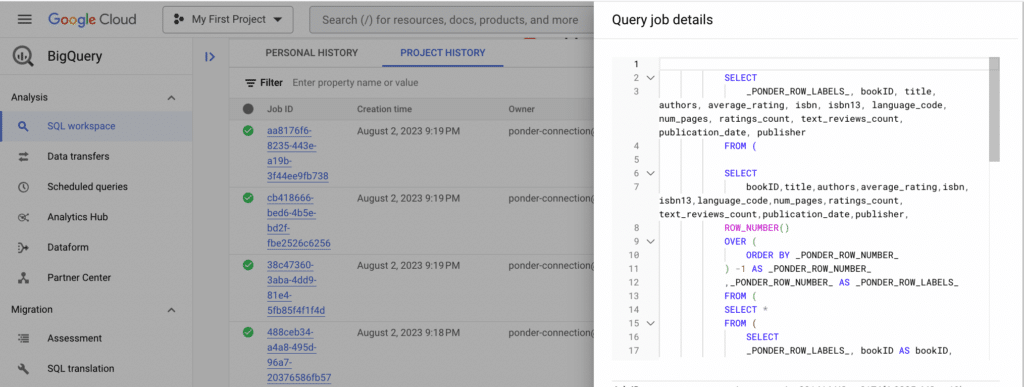
As we can see here, Ponder preserves the pandas API, so that you get the exact look-and-feel of working with pandas. The magic here is that all of this is happening on BigQuery!
Don’t believe this? Take a look at the BigQuery Project History after running the previous pandas command and you can find the SQL query that was generated by Ponder and executed on BigQuery, all fully automatically.
Significant Performance Improvement Compared to Pandas
Ponder translates your pandas workflows to SQL and runs it directly on BigQuery. In doing so, we avoid expensive data movement since data does not have to be pulled into memory. This leads to orders-of-magnitude performance improvement when working with a large dataset.
To demonstrate this performance improvement, we perform a benchmark on a 150M rows of the TPC-H dataset in BigQuery and compare this with using vanilla pandas.
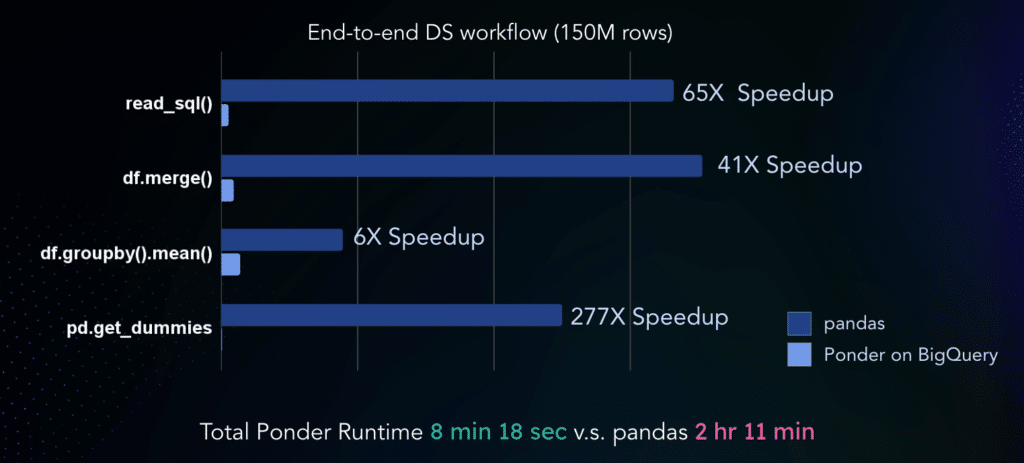
Here is the detailed comparison of the runtime for each query:

We can see that with pandas, the bulk of the time is spent on data movement when doing pd.read_sql. With the normal BigQuery Python workflow, it takes over 50 minutes to pull the data out of BigQuery to simply load the data into our dataframe in-memory. In comparison, this operation takes less than a minute with Ponder since there’s no data movement costs when we run pd.read_sql.
Note that even though there are two operations (describe, resample.count) that are about a minute slower in BigQuery than in pandas, this is happening for queries where pandas is already pretty fast, so the absolute time difference is not significant. When we look at operations where pandas is extremely slow and time-consuming (such as joins, index lookups, and one-hot encoding), we see significant speedups for those operations.
Overall, there was a ~16X performance improvement across the entire workflow. We saved more than two hours of development time by using Ponder on BigQuery when compared to using pandas! That is more time that could be put towards developing more models, getting more insights, and iterating on your workflows and pipelines!
BigQuery Python Data Science Work Has Never Been Easier
With Ponder 0.2.0 now supporting BigQuery, you can seamlessly work with your data directly in BigQuery using the familiar pandas interface while taking advantage of the scale and security that BigQuery provides.
Ponder removes the headache of having to move your data out of BigQuery for in-memory processing by pushing the computation down to BigQuery, so that the data warehouse does all the heavy lifting.
Get started today by checking out our getting started guide to see how you can begin running pandas on BigQuery in less than 5 minutes!
Try Ponder Today
Start running your Python data science workflows in your database within minutes!



