

On Monday, November 28th, Amazon announced at its re:Invent 2022 conference that Modin will be offered as a part of AWS Glue and SDK for Pandas. Since this is a huge accomplishment for the Modin project, I wanted to take the opportunity to explain the significance of this milestone, and reflect a bit on the journey and what this means to me personally.
It’s Easier than Ever to Use Modin with AWS
Running Pandas on large datasets has always been challenging, which is why we created Modin, the scalable drop-in replacement for Pandas. Yesterday, AWS announced two changes that make it easier than ever to use Modin with AWS:
- The AWS SDK for Pandas now supports Modin for scalable Pandas-related data wrangling jobs.
- AWS announced that AWS Glue (which has multiple uses, one of which is for distributed ETL) now ships with Modin on a managed Ray cluster.
This excerpt from this AWS blog post describes why Modin is such an important complement to Ray:
“Although Ray opens the door to big data processing, it’s not enough on its own to distribute pandas-specific methods. That task falls to Modin, a drop-in replacement of pandas, optimized to run in a distributed environment, such as Ray. Modin has the same API as pandas, so you can keep your code the same, but it parallelizes workloads to improve performance.” — AWS Big Data Blog
What impact this has depends on who you are, so let’s break this down by user type:
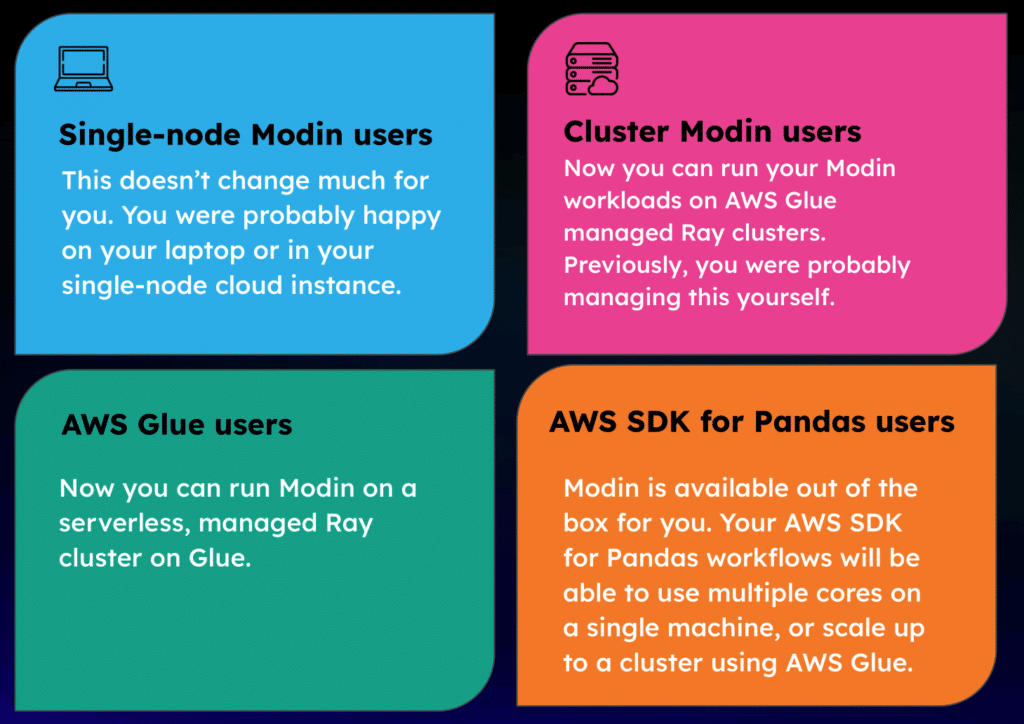
This is great news for the Modin community more broadly. For one thing, it means our community is growing, and with that comes increased attention from developers, which is likely to yield new features, more bug fixes, etc. I’m excited to see what kinds of workloads end up being enabled now that there’s a fully managed service available for Modin on Ray.
How we got here
I started Modin in 2018 — two years into my PhD. After talking with a bunch of my data scientist friends, I realized that new tools kept requiring data scientists to change how they reason about data in fundamental ways, when data scientists wanted to be spending their time extracting value from data. Modin was born from these observations. Pinning Modin’s API to the Pandas API forced us to innovate with the constraint that we meet Pandas users’ expectations.

There are loads of interesting technical challenges involved in directly scaling Pandas workflows. For example, Modin can support DataFrames with billions of columns, which is four to five orders of magnitude more than what most relational databases, including Apache Spark, can support. Modin was designed to support key features like this – so we have implemented interesting ways of handling metadata because the core data model is able to treat columns and rows interchangeably. I co-wrote a couple of papers [1, 2] on some of the interesting work we have done in Modin, and there are tons of exciting improvements still to come.
I never could have guessed that a project I started would have 8K Github stars, 4.6 million installs, and be hosted by a major cloud provider. This never would have happened if it weren’t for the Modin community we have built around supporting data science workloads at scale. Fundamentally we at Ponder are still focused on solving a really hard problem: to empower data scientists to be able to do more with what they already know. Focusing on the problem (rather than any specific outcome) is what has allowed Modin to have such a huge impact on the data science community already.
If you want to learn more about this change, check out our Scalable Pandas on AWS Meetup, with guest speaker Chris Fregly (Principal Solution Architect, AI and ML at AWS). And if you want to learn more about how Modin works, check out our write-up on how we parallelized the Pandas API and the recording from our Scalable Pandas Meetup on Modin.
It’s really exciting to see the major cloud providers adopt the ideals of data scientist empowerment, and we’re really excited to continue pushing what is possible with Python data science tools.



