

Introducing NumPy with Ponder
Last month, we announced that you can run pandas on your data warehouse of choice (Snowflake, BigQuery, etc.) using Ponder. Pandas on a terabyte? No sweat.
We are excited to share another announcement: Ponder now lets you run NumPy commands on your data warehouse as well. This means you can work with the NumPy API to build data and ML pipelines, and let Snowflake / BigQuery / Redshift take care of scaling, security, and compliance.
Why Pandas and NumPy?
Pandas and NumPy are the two most popular Python data science libraries. Here’s why:
- Sheer downloads: NumPy and pandas are each downloaded over 100 million times per month, with cumulative downloads for each in the 2.5-3.5 billion range.
- The Python Developer Survey (Python-specific): When asked which data science frameworks and libraries they use, 60% of Python developers said NumPy, and 55% said pandas, making those number one and two — above Matplotlib, SciPy, SciKit-Learn, TensorFlow, PyTorch, etc.
- The Stack Overflow Developer Survey (not Python-specific): When software developers were asked about the “other frameworks and libraries” they’ve used extensively in the past year or want to use in the coming year, ~29% said NumPy and ~25.0% said pandas, putting those at the top of the Python list.1
Members of the core NumPy team wrote in a 2020 Nature article that “NumPy underpins almost every Python library that does scientific or numerical computation, including SciPy, Matplotlib, pandas, scikit-learn and scikit-image.”
We are bringing the scale, security, and compliance benefits of modern data warehouses to NumPy.
What Can You Do with Ponder’s NumPy Implementation?
Ponder has implemented many of the most fundamental NumPy operations, which are essentially the building blocks of linear algebra. And linear algebra, in turn, is the backbone of machine learning. As MIT professor Gilbert Strang wrote in his “Matrix Methods” course description: “Linear algebra concepts are key for understanding and creating machine learning algorithms, especially as applied to deep learning and neural networks.”
Some of the operations Ponder’s NumPy implementation already supports are:
- Element-wise matrix operations such as addition, subtraction, multiplication, division, power
- Axis-collapsing or reducing operations such as min, max, sum, product, mean
- Multi-array operations such as maximum or minimum
- And many others, such as where, ravel, and transpose
Want to multiply or divide two enormous matrices? Want to transpose a matrix? Want to create a GPT implementation using NumPy’s linear algebra capabilities? Now you can with Ponder! By supporting NumPy on data warehouses, we sidestep both the memory constraint of working with native NumPy, as well as the performance and monetary costs of intermixing NumPy code with distributed code, by ensuring the data never leaves the warehouse, and forcing computation to occur in-warehouse.
Examples of NumPy with Ponder
Here are a few screenshots of Ponder in action, working on a 15-million-row dataframe in our data warehouse that we first convert to a NumPy array:
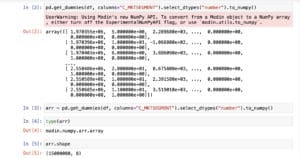
You can take the transpose of an array, or perform operations like taking the hyperbolic tangent of every element (useful in machine learning) or the exponent of every element.

You can take the sum over a particular axis of a 2D array, or sum the array in its entirety.
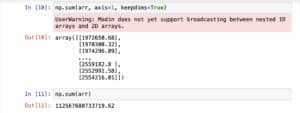
All low latency. All done in your data warehouse.
How Did We Make This Work?
Scaling NumPy to work on data warehouses presents two key challenges: How to ensure coverage for NumPy’s extensive API, and how to translate NumPy’s representation of data to align with the representation of data presented by databases.
At Ponder, we already have experience dealing with the first type of challenge from initially architecting pandas on a database. By utilizing our dataframe algebra – the narrow waistline that translates from pandas’ extensive API to the various computation engines we support, including Snowflake – we are able to create a lightweight API layer for NumPy that comes with out of the box support for many APIs that overlap with pandas. By expanding our algebra to encompass the more linear algebra and array oriented operations NumPy excels at, we can cover a larger portion of the NumPy API, allowing you to use your favorite NumPy APIs directly in the warehouse.
The second challenge present has to do with the modality of the data. NumPy APIs and users expect a contiguous, N-dimensional array-based layout of data, while databases make no guarantees to users about the location or physical layout of data. In order to support the matrix view that NumPy offers users, it was important to decouple the physical layout of the data from the view presented to users. Additionally, while NumPy arrays support column-major and row-major lookup, databases traditionally present a row-major view of data, requiring us to incorporate additional metadata to our NumPy API in order to present users with the same data abstractions they are familiar with.
Conclusion
With Ponder, your data gets executed directly IN the warehouse, meaning that we inherit the scalability and security benefits of the database, but let you work with your favorite data science APIs: Pandas, and now important parts of the NumPy API, with more NumPy commands to come. Ultimately, Ponder aims to let you run any data science library at scale on your existing infrastructure.
If you want to experience running scalable pandas + NumPy on your data warehouse, sign up to try Ponder today!
Footnote 1: These were housed in the “other frameworks” section simply because respondents had already been asked about “programming, scripting, and markup languages,” “databases,” “cloud platforms,” and “web frameworks.”



